1. The Main Elements of Client-side Application Components Of Distributed Systems

- Client-side refers to operations that are performed by the client in a client–server relationship in a computer network.
- Typically, a client is a computer application, such as a web browser, that runs on a user's local computer, smartphone, or other device, and connects to a server as necessary. Operations may be performed client-side because they require access to information or functionality that is available on the client but not on the server, because the user needs to observe the operations or provide input, or because the server lacks the processing power to perform the operations in a timely manner for all of the clients it serves. Additionally, if operations can be performed by the client, without sending data over the network, they may take less time, use less bandwidth, and incur a lesser security risk.
- Distributed computing projects such as SETI@home and the Great Internet Mersenne Prime Search, as well as Internet-dependent applications like Google Earth, rely primarily on client-side operations. They initiate a connection with the server (either in response to a user query, as with Google Earth, or in an automated fashion, as with SETI@home), and request some data. The server selects a data set (a server-side operation) and sends it back to the client. The client then analyzes the data (a client-side operation), and, when the analysis is complete, displays it to the user (as with Google Earth) and/or transmits the results of calculations back to the server.
Page Element Level
- Page Elements are the counter parts to the XML elements that are transferred as layout definition from the server to the client. The client side framework maintains a page element tree which is 100% in synch with the XML layout definition that is managed on server side. This means: every time that new XML is received from the server, then corresponding updated are made inside the page element tree – page elements may be destroyed, if they are not contained in the layout anymore, they may be created if they are newly available and they are updated when there is a change of attribute values.
Page Element Classes
- In order to simplify the creation of page elements and in order to properly arrange page elements within the layout management there are already some very useful page elements, that you should use for deriving your own components.
2. The Views Development Technologies for The Browser-based Client-components of Web-based Applications
jQuery

- jQuery is a JavaScript library designed to simplify HTML DOM tree traversal and manipulation, as well as event handling, CSS animation, and Ajax. It is free, open-source software using the permissive MIT License. Web analysis indicates that it is the most widely deployed JavaScript library by a large margin.
- jQuery's syntax is designed to make it easier to navigate a document, select DOM elements, create animations, handle events, and develop Ajax applications. jQuery also provides capabilities for developers to create plug-ins on top of the JavaScript library. This enables developers to create abstractions for low-level interaction and animation, advanced effects and high-level, themeable widgets. The modular approach to the jQuery library allows the creation of powerful dynamic web pages and Web applications.
- jQuery, at its core, is a Document Object Model (DOM) manipulation library. The DOM is a tree-structure representation of all the elements of a Web page. jQuery simplifies the syntax for finding, selecting, and manipulating these DOM elements. For example, jQuery can be used for finding an element in the document with a certain property (e.g. all elements with an h1 tag), changing one or more of its attributes (e.g. color, visibility), or making it respond to an event (e.g. a mouse click).
- jQuery also provides a paradigm for event handling that goes beyond basic DOM element selection and manipulation. The event assignment and the event callback function definition are done in a single step in a single location in the code. jQuery also aims to incorporate other highly used JavaScript functionality.
Bootstrap

- Bootstrap is a free and open-source CSS framework directed at responsive, mobile-first front-end web development. It contains CSS- and JavaScript-based design templates for typography, forms, buttons, navigation and other interface components.
- Bootstrap is a web framework that focuses on simplifying the development of informative web pages (as opposed to web apps). The primary purpose of adding it to a web project is to apply Bootstrap's choices of color, size, font and layout to that project. As such, the primary factor is whether the developers in charge find those choices to their liking. Once added to a project, Bootstrap provides basic style definitions for all HTML elements. The end result is a uniform appearance for prose, tables and form elements across web browsers. In addition, developers can take advantage of CSS classes defined in Bootstrap to further customize the appearance of their contents. For example, Bootstrap has provisioned for light- and dark-colored tables, page headings, more prominent pull quotes, and text with a highlight.
- Bootstrap also comes with several JavaScript components in the form of jQuery plugins. They provide additional user interface elements such as dialog boxes, tooltips, and carousels. Each Bootstrap component consists of an HTML structure, CSS declarations, and in some cases accompanying JavaScript code. They also extend the functionality of some existing interface elements, including for example an auto-complete function for input fields.
- A precompiled version of Bootstrap is available in the form of one CSS file and three JavaScript files that can be readily added to any project. The raw form of Bootstrap, however, enables developers to implement further customization and size optimizations. This raw form is modular, meaning that the developer can remove unneeded components, apply a theme and modify the uncompiled Sass.
Angular

- Angular is a TypeScript-based open-source web application framework led by the Angular Team at Google and by a community of individuals and corporations. Angular is a complete rewrite from the same team that built AngularJS.
- HTML is great for declaring static documents, but it falters when we try to use it for declaring dynamic views in web-applications. AngularJS lets you extend HTML vocabulary for your application. The resulting environment is extraordinarily expressive, readable, and quick to develop.
- Other frameworks deal with HTML’s shortcomings by either abstracting away HTML, CSS, and/or JavaScript or by providing an imperative way for manipulating the DOM. Neither of these address the root problem that HTML was not designed for dynamic views.
- AngularJS is a toolset for building the framework most suited to your application development. It is fully extensible and works well with other libraries. Every feature can be modified or replaced to suit your unique development workflow and feature needs. Read on to find out how.
React

- React is a JavaScript library for building user interfaces. It is maintained by Facebook and a community of individual developers and companies.
jQuery UI

- jQuery UI is a collection of GUI widgets, animated visual effects, and themes implemented with jQuery, Cascading Style Sheets, and HTML. According to JavaScript analytics service, Libscore, jQuery UI is used on over 197,000 of the top one million websites, making it the second most popular JavaScript library.
4. The Client-model Development Technologies for The Browser-based Client-components of Web-based Applications
HTML
- HTML (HyperText Markup Language) is the standard markup language used to create web pages and web applications. Its elements form the building blocks of pages, representing formatted text, images, form inputs, and other structures. When a browser makes a request to a URL, whether fetching a page or an application, the first thing that is returned is an HTML document. This HTML document may reference or include additional information about its look and layout in the form of CSS, or behavior in the form of JavaScript.
CSS

- CSS (Cascading Style Sheets) is used to control the look and layout of HTML elements. CSS styles can be applied directly to an HTML element, defined separately on the same page, or defined in a separate file and referenced by the page. Styles cascade based on how they are used to select a given HTML element. For instance, a style might apply to an entire document, but would be overridden by a style that applied to a particular element. Likewise, an element-specific style would be overridden by a style that applied to a CSS class that was applied to the element, which in turn would be overridden by a style targeting a specific instance of that element (via its id).
Javascript

- JavaScript is a dynamic, interpreted programming language that has been standardized in the ECMAScript language specification. It is the programming language of the web. Like CSS, JavaScript can be defined as attributes within HTML elements, as blocks of script within a page, or in separate files. Just like CSS, it's generally recommended to organize JavaScript into separate files, keeping it separated as much as possible from the HTML found on individual web pages or application views.
- You can perform all of these tasks with JavaScript alone, but many libraries exist to make these tasks easier. One of the first and most successful of these libraries is jQuery, which continues to be a popular choice for simplifying these tasks on web pages. For Single Page Applications (SPAs), jQuery doesn't provide many of the desired features that Angular and React offer.

5. Different Categories of Elements in HTML
HTML Elements
- An HTML element usually consists of a start tag and end tag, with the content inserted in between
<tagname>Content goes here...</tagname>

Nested HTML Elements
- HTML elements can be nested (elements can contain elements).
- All HTML documents consist of nested HTML elements.
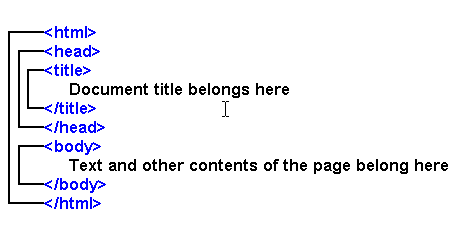

Empty HTML Elements
- HTML elements with no content are called empty elements.
- Empty elements can be "closed" in the opening tag like this: <br />.


6. Importance of CSS

Improves website presentation
- The standout advantage of CSS is the added design flexibility and interactivity it brings to web development. Developers have greater control over the layout allowing them to make precise section-wise changes.
- As customization through CSS is much easier than plain HTML, web developers are able to create different looks for each page. Complex websites with uniquely presented pages are feasible thanks to CSS.
Makes updates easier and smoother
- CSS works by creating rules. These rules are simultaneously applied to multiple elements within the site. Eliminating the repetitive coding style of HTML makes development work faster and less monotonous. Errors are also reduced considerably.
- Since the content is completely separated from the design, changes across the website can be implemented all at once. This reduces delivery times and costs of future edits.
Helps web pages loads faster
- Improved website loading is an underrated yet important benefit of CSS. Browsers download the CSS rules once and cache them for loading all the pages of a website. It makes browsing the website faster and enhances the overall user experience.
- This feature comes in handy in making websites work smoothly at lower internet speeds. Accessibility on low end devices also improves with better loading speeds.
New features of CSS3

- The latest version of Cascade Style Sheets, CSS 3, was developed to make Web design easier but it became a hot topic for a while because not all browsers supported it. However, trends change quickly in technology and all browser makers currently are implementing complete CSS 3 support. Making that process easier for the browser manufacturers is CSS 3's modularized specification, which allows them to provide support for modules incrementally without having to perform major refactoring of the browsers' codebases. The modularization concept not only makes the process of approving individual CSS 3 modules easier and faster, but it also makes documenting the spec easier.
CSS3 Selectors
- In addition to the selectors that were available in CSS2, CSS 3 introduces some new selectors. Using these selectors you can choose DOM elements based on their attributes. So you don't need to specify classes and IDs for every element. Instead, you can utilize the attribute field to style them.
[attr^=val]–- matches a DOM element with the attributeattrand a value starting withval[attr$=val]–- matches a DOM element with the attributeattrand a value ending with the suffixval[attr*=val]–- matches a DOM element with the attributeattrand a value containing the substringval
CSS3 Rounded Corners
- Rounded corner elements can spruce up a website, but creating a rounded corner requires a designer to write a lot of code. Adjusting the height, width and positioning of these elements is a never-ending chore because any change in content can break them.
- CSS 3 addresses this problem by introducing the border-radius property, which gives you the same rounded-corner effect and you don't have to write all the code. Here are examples for displaying rounded corners in different places of a website.
CSS3 Box Shadows
- A box shadow allows you to create a drop shadow for an element. Usually this effect is achieved using a repeated image around the element. However, with the property box-shadow this can be achieved by writing a single line of CSS code.
- After previously removing this property from the CSS 3 Backgrounds and Borders Module, the W3C added it back in the last working draft.
7. 3 Main Types of CSS Selectors
- CSS selectors are used to "find" (or select) HTML elements based on their element name, id, class, attribute, and more.

The Element Selector
- The element selector selects elements based on the element name. You can select all <p> elements on a page like this (in this case, all <p> elements will be center-aligned, with a red text color)
p {
text-align: center;
color: red;
}

The id Selector
- The id selector uses the id attribute of an HTML element to select a specific element. The id of an element should be unique within a page, so the id selector is used to select one unique element! To select an element with a specific id, write a hash (#) character, followed by the id of the element. The style rule below will be applied to the HTML element with id="para1":
#para1 {
text-align: center;
color: red;
}

The Class Selector
- The class selector selects elements with a specific class attribute. To select elements with a specific class, write a period (.) character, followed by the name of the class. In the example below, all HTML elements with class="center" will be red and centeraligned:
.center {
text-align: center;
color: red;
}
- You can also specify that only specific HTML elements should be affected by a class. In the example below, only <p> elements with class="center" will be center-aligned:
p.center {
text-align: center;
color: red;
}
- HTML elements can also refer to more than one class. In the example below, the <p> element will be styled according to class="center" and to class="large":
<p class="center large">This paragraph refers to two classes.</p>

8. Advanced CSS Selectors

- Selectors are used for selecting the HTML elements in the attributes. Some different types of selectors are given below:
Adjacent Sibling Selector
- It selects all the elements that are adjacent siblings of specified elements. It selects the second element if it immediately follows the first element.
- It select ul tags which immediately follows the h4 tag.
h4+ul{
border: 4px solid red;
}
Example
<!DOCTYPE html>
<html>
<head>
<title>adjacent</title>
<style type="text/css">
ul+h4{
border:4px solid red;
}
</style>
</head>
<body>
<h1>GeeksForGeeks</h1>
<ul>
<li>Language</li>
<li>Concept</li>
<li>Knowledge</li>
</ul>
<h4>Coding</h4>
<h2>Time</h2>
</body> <
</html>

Attribute Selector
- It selects a particular type of inputs.
Syntax
input[type="checkbox"]{
background:orange;
}
Example
<html>
<head>
<title>Attribute</title>
<style type="text/css">
a[href="http://www.google.com"]{
background:yellow;
}
</style>
</head>
<body>
<a href="http://www.google.com" target="_blank">google.com</a>
<br>
<a href="http://www.wikipedia.org" target="_top">wikipedia.org</a>
</body>
</html>

nth-of-type Selector
- It selects an element from its position and types.
Syntax
- Select a particular number tag to make changes.
div:nth-of-type(5){
background:purple;
}
- If we want to make canges in all even li.
li:nth-of-type(even){
background: yellow;
}
Example
<html>
<head>
<title>nth</title>
<style type="text/css">
ul:nth-of-type(2){
background:yellow;
}
</style>
</head>
<body>
<ul>
<li>java</li>
<li>python</li>
<li>C++</li>
</ul>
<ul>
<li>HTML</li>
<li>CSS</li>
<li>PHP</li>
</ul>
<ul>
<li>C#</li>
<li>R</li>
<li>Matlab</li>
</ul>
</body>
</html>
9. The Use For CSS Media Queries in Responsive Web Development
- By targeting the browser width, we can style content to look appropriate for a wide desktop browser, a medium-sized tablet browser, or a small phone browser. Adjusting the layout of a web page based on the width of the browser is called "responsive design." Responsive design is made possible by CSS media queries.
- One of these tricks is the use of media queries, which work to call styles to the user device based on its dimensions. There has been some debate in the past on whether media queries are the best solution when it comes to mobile first, and that debate still continous. However, the Responsive Issues Community Group (RICG) and W3C have looked at ways to implement element queries, which some belleve would be a better solution. Why? Because they don’t depend on the viewport, but on the container within it. Media queries are a simple and effective way to serve different content to a range of devices and the most commonly used queries are those that deal with the viewport’s height and width.
10. The Pros and Cons of 3 Ways of Using CSS (inline, internal, external)
Inline CSS

Advantages
Testing
- Many web designers use Inline CSS when they begin working on new projects, this is because its easier to scroll up in the source, rather than change the source file. Some also using it to debug their pages, if they encounter a problem which is not so easily fixed. This can be done in combination with the Important rule of CSS.
Quick fixes
- There are times where you would just apply a direct fix in your HTML source, using the style attribute, but you would usually move the fix to the relevant files when you are either able, or got the time.
Smaller websites
- The website such as Blogs where there are only limited number of pages, using of Inline CSS helps users and service provider
Lower the HTTP requests
- The major benefit of using Inline CSS is lower HTTP Requests which means the website loads faster than External CSS.
Disadvantages
Overriding
- Because they are the most specific in the cascade, they can over-ride things you didn’t intend them to.
Every Element
- Inline styles must be applied to every element you want them on. So if you want all your paragraphs to have the font family “Arial” you have to add an inline style to each <p> tag in your document. This adds both maintenance work for the designer and download time for the reader.
Pseudo elements
- It’s impossible to style pseudo-elements and classes with inline styles. For example, with external and internal style sheets, you can style the visited, hover, active, and link color of an anchor tag. But with an inline style all you can style is the link itself, because that’s what the style attribute is attached to.
Internal CSS

Advantages
Cache Problem
- Internal styles will be read by all browsers unless they are hacked to hide from certain ones. This removes the ability to use media=all or @import to hide styles from old, crotchety browsers like IE4 and NN4.
Pseudo Elements
- It’s impossible to style pseudo-elements and classes with inline styles. With Internal style sheets, you can style the visited, hover, active, and link color of an anchor tag.
One style of same element
- Internal styles need not be applied to every element. So if you want all your paragraphs to have the font family “Arial” you have to add an Inline style <p> tag in Internal Style document.
Disadvantages
Multiple documents
- This method can’t be used, if you want to use it on multiple web pages.
Slow page loading
- As there are less HTTP Request but by using the Internal CSS the page load slow as compared to Inline and External CSS.
Large file size
- While using the Internal CSS the page size increases but it helps only to Designers while working offline but when the website goes online it consumers much time as compared to offline.
External CSS

Advantages
Full Control of page structure
- CSS allows you to display your web page according to W3C HTML standards without making any compromise with the actual look of the page. Google is the leading search Engine and major source of traffic. Google gives very little value to the web pages that are well-organized, since the value is little thus many Designers ignore it. But by taking small value may drive much traffic to the website.
Reduced file size
- By including the styling of the text in a separate file, you can dramatically decrease the file-size of your pages. Also, the content-to-code ratio is far greater than with simple HTML pages, thus making the page structure easier to read for both the programmer and the spiders. With CSS you can define the visual effect that you want to apply to images, instead of using images per say. The space you gain this way can be used for text that is relevant for spiders (i.e. keywords), and you will also lower the file-size of the page.
Higher page ranking
- In the SEO, it is very important to use external CSS. How it gives, let me explain, In SEO, the content is the King and not the amount of code on a page. Search engines spider will be able to index your pages much faster, as the important information can be placed higher in the HTML document. Also, the amount of relevant content will be greater than the amount of code on a page. The search engine will not have to look too far in your code to find the real content. You will be actually serving it to the spiders “on a platter”. CSS will help you create highly readable pages, rich in content, which will prove extremely helpful in your SEO campaign. As you very well know, better site ranking means better visibility on the web, and this can translate into more visitors and, ultimately, into increased sales or number of contracts. For more details lets use some code to understand.
Disadvantages
- The disadvantages are that it may decrease loading time in some situations. It may also not be practical if there are not enough styling conditions to justify an external sheet.
- In order to import style information for each document, an extra download is needed.
- Until the external style sheet is loaded, it may not be possible to render the document.
- For small number of style definitions, it is not viable.
- Increased page loading time.
- It affects only one page – not useful if you want to use the same CSS on multiple documents.
11. Frameworks , Libraries and Tools
Frameworks

- A framework is an application skeleton. It requires you to approach software design in a specific way and insert your own logic at certain points. Functionality such as events, storage, and data binding are normally provided for you. Using the car analogy, a framework provides a working chassis, body, and engine. You can add, remove or tinker with some components presuming the vehicle remains operational.
- A framework normally provides a higher level of abstraction than a library and can help you rapidly build the first 80% of your project. The downsides:
- the last 20% can be tough going if your application moves beyond the confines of the framework
- framework updates or migrations can be difficult – if not impossible
- core framework code and concepts rarely age well. Developers will always discover a better way to do the same thing.
Libraries

- A library is an organized collection of useful functionality. A typical library could include functions to handle strings, dates, HTML DOM elements, events, cookies, animations, network requests, and more. Each function returns values to the calling application which can be implemented however you choose. Think of it like a selection of car components: you’re free to use any to help construct a working vehicle but you must build the engine yourself.
- Libraries normally provide a higher level of abstraction which smooths over implementation details and inconsistencies. For example, Ajax can be implemented using the XMLHttpRequest API but this requires several lines of code and there are subtle differences across browsers. A library may provide a simpler ajax() function so you’re free to concentrate on higher-level business logic.
- A library could cut development time by 20% because you don’t have to worry about the finer details. The downsides:
- a bug within a library can be difficult to locate and fix
- there’s no guarantee the development team will release a patch quickly
- a patch could change the API and incur significant changes to your code.
Tools

- A tool aids development but is not an integral part of your project. Tools include build systems, compilers, transpilers, code minifiers, image compressors, deployment mechanisms and more.
- Tools should provide an easier development process. For example, many coders prefer Sass to CSS because it provides code separation, nesting, render-time variables, loops, and functions. Browsers do not understand Sass/SCSS syntax so the code must be compiled to CSS using an appropriate tool before testing and deployment.
12. The Client-side Component Development Related Aspects in Browser-based Web Applications
- There is a wide range of web-based applications available, and their numbers continue to grow. Well-known types of software you can find in web-based versions are email applications, word processors, spreadsheet apps, and a host of other office productivity tools.
- For example, Google offers a suite of office productivity applications in a style most people are already familiar with. Google Docs is a word processor, and Google Sheets is a spreadsheet application.
- Microsoft's ubiquitous office suite has a web-based platform known as Office Onlineand Office 365. Office 365 is a subscription service. Web-based tools can also make meetings and collaborations vastly easier. Applications such as WebEx and GoToMeeting make setting up and running an online meeting easy.

13. The New Features in JS Version 6
- Some of [ECMAScript 6’s] major enhancements include modules, class declarations, lexical block scoping, iterators and generators, promises for asynchronous programming, destructuring patterns, and proper tail calls. The ECMAScript library of built-ins has been expanded to support additional data abstractions including maps, sets, and arrays of binary numeric values as well as additional support for Unicode supplemental characters in strings and regular expressions. The built-ins are now extensible via subclassing.

- You can now specify integers in binary and octal notation:
> 0xFF // ES5: hexadecimal
255
> 0b11 // ES6: binary
3
> 0o10 // ES6: octal
8
- A method and constants for determining whether a JavaScript integer is safe(within the signed 53 bit range in which there is no loss of precision):
Number.isSafeInteger(number)Number.MIN_SAFE_INTEGERNumber.MAX_SAFE_INTEGER
Number.isNaN(num)checks whethernumis the valueNaN. In contrast to the global functionisNaN(), it doesn’t coerce its argument to a number and is therefore safer for non-numbers:
> isNaN('???')
true
> Number.isNaN('???')
false
- The global object
Mathhas new methods for numerical, trigonometric and bitwise operations. Let’s look at examples.
> Math.sign(-8)
-1
> Math.sign(0)
0
> Math.sign(3)
1
> Math.trunc(3.1)
3
> Math.trunc(3.9)
3
> Math.trunc(-3.1)
-3
> Math.trunc(-3.9)
-3
- New string methods:
> 'hello'.startsWith('hell')
true
> 'hello'.endsWith('ello')
true
> 'hello'.includes('ell')
true
> 'doo '.repeat(3)
'doo doo doo '
- Symbols are mainly used as unique property keys – a symbol never clashes with any other property key (symbol or string). For example, you can make an object iterable (usable via the
for-ofloop and other language mechanisms), by using the symbol stored inSymbol.iteratoras the key of a method (more information on iterables is given in the chapter on iteration):
const iterableObject = {
[Symbol.iterator]() { // (A)
···
}
}
for (const x of iterableObject) {
console.log(x);
}
// Output:
// hello
// world
Destructuring objects:
constobj={first:'Jane',last:'Doe'};const{first:f,last:l}=obj;// f = 'Jane'; l = 'Doe'// {prop} is short for {prop: prop}const{first,last}=obj;// first = 'Jane'; last = 'Doe'
Array destructuring (works for all iterable values):
constiterable=['a','b'];const[x,y]=iterable;// x = 'a'; y = 'b'
Destructuring can be used in the following locations (I’m showing Array patterns to demonstrate; object patterns work just as well):
// Variable declarations:const[x]=['a'];let[x]=['a'];var[x]=['a'];// Assignments:[x]=['a'];// Parameter definitions:functionf([x]){···}f(['a']);
- A default parameter value is specified for a parameter via an equals sign (
=). If a caller doesn’t provide a value for the parameter, the default value is used. In the following example, the default parameter value ofyis 0:
functionfunc(x,y=0){return[x,y];}func(1,2);// [1, 2]func(1);// [1, 0]func();// [undefined, 0]