1 . The Role of Data in Information Systems Indicating The Need For Data Persistence

- Understanding the meaning of persistence is important for evaluating different data store systems.
- Persistence is the continuance of an effect after its cause is removed. In the context of storing data in a computer system, this means that the data survives after the process with which it was created has ended. In other words, for a data store to be considered persistent, it must write to non-volatile storage. .If you need persistence in your data store, then you need to also understand the four main design approaches that a data store can take and how (or if) these designs provide persistence:
- Pure in memory , no persistence at all such as memcached or scalaris
- In memory with periodic snapshots such as Oracle Coherence or Redis
- Disk based with update in placewrites such as MySQL ISAM or MongoDB
- In-memory approaches can achieve blazing speed, but at the cost of being limited to a relatively small data set. Most workloads have relatively small "hot" (active) subset of their total data; systems that require the whole dataset to fit in memory rather than just the active part are fine for caches but a bad fit for most other applications. Because the data is in memory only, it will not survive process termination. Therefore these types of data stores are not considered persistent.
- The easiest way to add persistence to an in-memory system is with periodic snapshots to disk at a configurable interval. Thus, you can lose up to that interval's worth of updates.
- This allows you do decide what the right trade off is between safety and performance. You can choose, for each write operation, to wait for that update to be buffered to memory, written to disk on a single machine, written to disk on multiple machines, or even written to disk on multiple machines in different data centers. Or, you can choose to accept writes a quickly as possible, acknowledging their receipt immediately before they have even been fully deserialized from the network.
2. Special Terms
Data

- Data is a set of values of subjects with respect to qualitative or quantitative variables. Data and information or knowledge are often used interchangeably; however data becomes information when it is viewed in context or in post-analysis.
- Data is distinct pieces of information, usually formatted in a special way. All software is divided into two general categories: data and programs. Programs are collection of instructionsfor manipulating data.
- Data can exist in a variety of forms — as numbers or text on pieces of paper, as bits and bytes stored in electronic memory, or as facts stored in a person's mind. Since the mid-1900s, people have used the word data to mean computer information that is transmitted or stored.
Database
- A database is an organized collection of data, generally stored and accessed electronically from a computer system. Where databases are more complex they are often developed using formal design and modeling techniques.
- A database (DB), in the most general sense, is an organized collection of data. More specifically, a database is an electronic system that allows data to be easily accessed, manipulated and updated. In other words, a database is used by an organization as a method of storing, managing and retrieving information. Modern databases are managed using a database management system (DBMS).
- Database architecture may be external, internal or conceptual. The external level specifies the way in which every end-user type comprehends the organization of its corresponding relevant data in the database. The internal level deals with the performance, scalability, cost and other operational matters. The conceptual level perfectly unifies the different external views into a defined and wholly global view. It consists of every end-user required generic data.
Database Server

- The term database server may refer to both hardware and software used to run a database, according to the context. As software, a database server is the back-end portion of a database application, following the traditional client-server model. This back-end portion is sometimes called the instance. It may also refer to the physical computer used to host the database. When mentioned in this context, the database server is typically a dedicated higher-end computer that hosts the database.
- Note that the database server is independent of the database architecture. Relational databases, flat files, non-relational databases: all these architectures can be accommodated on database servers.
Database Management System
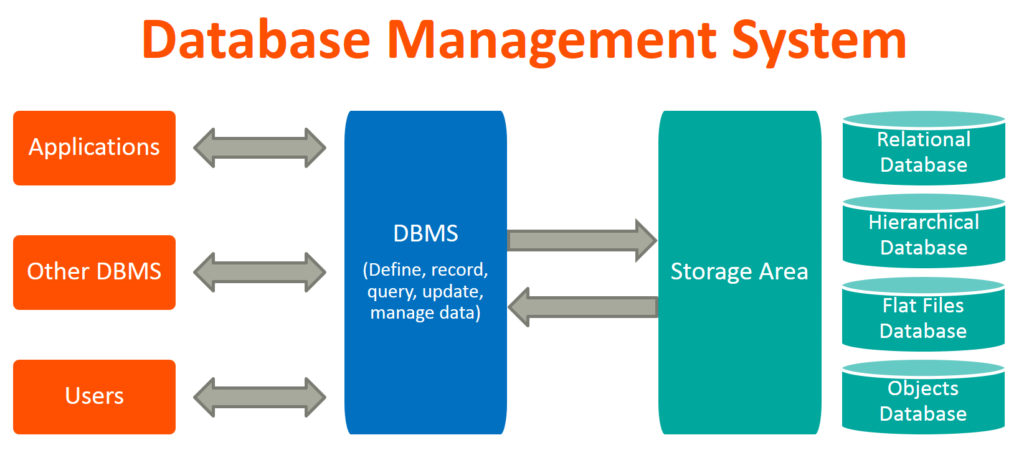
- A database management system (DBMS) is a software package designed to define, manipulate, retrieve and manage data in a database. A DBMS generally manipulates the data itself, the data format, field names, record structure and file structure. It also defines rules to validate and manipulate this data. A DBMS relieves users of framing programs for data maintenance. Fourth-generation query languages, such as SQL, are used along with the DBMS package to interact with a database.
- A database management system receives instruction from a database administrator (DBA) and accordingly instructs the system to make the necessary changes. These commands can be to load, retrieve or modify existing data from the system.
3. Files And Databases
Pros of File System
- Performance can be better than when we do it in a database - To justify this, if you store large files in DB, then it may slow down the performance because a simple query to retrieve the list of files or filename will also load the file data if you used select * in your query. In a files ystem, accessing a file is quite simple and light weight.
- Saving the files and downloading them in the file system is much simpler - than it is in a database since a simple "Save As" function will help you out. Downloading can be done by addressing a URL with the location of the saved file.
- Migrating data is an easy process - You can just copy and paste the folder to your desired destination while ensuring that write permissions are provided to your destination.
- Cost effective - in most cases to expand your web server rather than pay for certain databases.
- East to migrate into cloud - Amazon S3, CDNs, etc. in the future.
Pros of Databases
- ACID consistency - which includes a rollback of an update that is complicated when files are stored outside the database.
- Files will be in sync with the database - and cannot be orphaned, which gives you the upper hand in tracking transactions.
- Backups automatically include file libraries
- More Secure

Cons of File System
- Loosely coupled - There are no ACID (Atomicity, Consistency, Isolation, Durability) operations in relational mapping, which means there is no guarantee. Consider a scenario in which your files are deleted from the location manually or by some hacking dudes. You might not know whether the file exists or not. Painful, right?
- Low Security - Since your files can be saved in a folder where you should have provided write permissions, it is prone to safety issues and invites trouble, like hacking. It's best to avoid saving in the file system if you cannot afford to compromise in terms of security.
Cons of Databases
- Memory is ineffective - Often, RDBMSs are RAM-driven, so all data has to go to RAM first. Yeah, that’s right. Have you ever thought about what happens when an RDBMS has to find and sort data? RDBMS tracks each data page — even the lowest amount of data read and written — and it has to track if it’s in-memory or if it’s on-disk, if it’s indexed or if it's sorted physically etc.
- Database backups will be more hefty and heavy
- you may have to convert files into blob.
5. Different Types of Databases
Hierachical Databases

- In a hierarchical database management systems (hierarchical DBMSs) model, data is stored in a parent-children relationship nodes. In a hierarchical database, besides actual data, records also contain information about their groups of parent/child relationships.
- In a hierarchical database model, data is organized into a tree like structure. The data is stored in form of collection of fields where each field contains only one value. The records are linked to each other via links into a parent-children relationship. In a hierarchical database model, each child record has only one parent. A parent can have multiple children.
- The hierarchical database system structure was developed by IBM in early 1960s. While hierarchical structure is simple, it is inflexible due to the parent-child one-to-many relationship. Hierarchical databases are widely used to build high performance and availability applications usually in banking and telecommunications industries.
Network Databases
- Network database management systems (Network DBMSs) use a network structure to create relationship between entities. Network databases are mainly used on a large digital computers. Network databases are hierarchical databases but unlike hierarchical databases where one node can have one parent only, a network node can have relationship with multiple entities. A network database looks more like a cobweb or interconnected network of records.
- In network databases, children are called members and parents are called occupier. The difference between each child or member can have more than one parent. The approval of the network data model is similar to a hierarchical data model. Data in a network database is organized in many-to-many relationships. The network database structure was invented by Charles Bachman. Some of the popular network databases are Integrated Data Store (IDS), IDMS (Integrated Database Management System), Raima Database Manager, TurboIMAGE, and Univac DMS-1100.

Relational Databases
- In relational database management systems (RDBMS), the relationship between data is relational and data is stored in tabular form of columns and rows. Each column if a table represents an attribute and each row in a table represents a record. Each field in a table represents a data value.
- Structured Query Language (SQL) is a the language used to query a RDBMS including inserting, updating, deleting, and searching records. Relational databases work on each table has a key field that uniquely indicates each row, and that these key fields can be used to connect one table of data to another. Relational databases are the most popular and widely used databases. Some of the popular DDBMS are Oracle, SQL Server, MySQL, SQLite, and IBM DB2.

Graph Databases
- Graph Databases are NoSQL databases and use a graph structure for sematic queries. The data is stored in form of nodes, edges, and properties. In a graph database, a Node represent an entity or instance such as customer, person, or a car. A node is equivalent to a record in a relational database system. An Edge in a graph database represents a relationship that connects nodes. Properties are additional information added to the nodes.
- The Neo4j, Azure Cosmos DB, SAP HANA, Sparksee, Oracle Spatial and Graph, OrientDB, ArrangoDB, and MarkLogic are some of the popular graph databases. Graph database structure is also supported by some RDBMs including Oracle and SQL Server 2017 and later versions.

ER Model Database
- An ER model is typically implemented as a database. In a simple relational database implementation, each row of a table represents one instance of an entity type, and each field in a table represents an attribute type. In a relational database a relationship between entities is implemented by storing the primary key of one entity as a pointer or "foreign key" in the table of another entity. Entity-relationship model was developed by Peter Chen 1976.

Document Databases
- Document databases (Document DB) are also NoSQL database that store data in form of documents. Each document represents the data, its relationship between other data elements, and attributes of data. Document database store data in a key value form. Document DB has become popular recently due to their document storage and NoSQL properties. NoSQL data storage provide faster mechanism to store and search documents. Popular NoSQL databases are Hadoop/Hbase, Cassandra, Hypertable, MapR, Hortonworks, Cloudera, Amazon SimpleDB, Apache Flink, IBM Informix, Elastic, MongoDB, and Azure DocumentDB.

6. Big Data Vs Data Warehouse
- The first thing we need to define is the term “big data” which pretty much defines itself. You’ve probably heard the often-cited statistic that 90% of all data has been created in the past 2 years. That’s big data. All the ginormous sets of data exhaust that are now being generated can be mined (remember data mining?) to extract insights. In today’s high-tech world, we might want to generate insights that we don’t know exist. Donald Rumsfeld cleverly referred to these as the “unknown unknowns,” things we don’t know we don’t know about. In the world of psychology, this concept is referred to as the Johari Window. You know that person in sales who is unaware of the fact that their mere existence makes everyone around them want to pull a Peter Pan off the nearest high-rise? The fact that the person is unaware of how annoying they are – and the fact that the people around that person can’t exactly put their finger on why – is an “unknown unknown” in that nobody knows why Rob in sales is just a big, fat, obnoxious prick. Anyways, moving on.
- Data Warehouse is an architecture of data storing or data repository. Whereas Big Data is a technology to handle huge data and prepare the repository.
- Any kind of DBMS data accepted by Data warehouse, whereas Big Data accept all kind of data including transnational data, social media data, machinery data or any DBMS data.
- Data warehouse only handles structure data (relational or not relational), but big data can handle structure, non-structure, semi-structured data.
- Big data normally used a distributed file system to load huge data in a distributed way, but data warehouse doesn’t have that kind of concept.
- From a business point of view, as big data has a lot of data, analytics on that will be very fruitful, and the result will be more meaningful which help to take proper decision for that organization. Whereas Data warehouse mainly helps to analytic on informed information.
- Data warehouse means the relational database, so storing, fetching data will be similar with normal SQL query. And big data is not following proper database structure, we need to use hive or spark SQL to see the data by using hive specific query.
- 100% data loaded into data warehousing are using for analytics reports. But whatever data loaded by Hadoop, maximum 0.5% used on analytics reports till now. Others data are loaded into the system, but in not use status.
- Data Warehousing never able to handle humongous data (totally unstructured data). Big data (Apache Hadoop) is the only option to handle humongous data.
- The timing of fetching increasing simultaneously in data warehouse based on data volume. Means, it will take small time for low volume data and big time for a huge volume of data just like DBMS. But in case of big data, it will take a small period of time to fetching huge data (as it specially designed for handling huge data), but taken huge time if we somehow try to load or fetch small data in HDFS by using map reduce.
8. SQL Statements, Prepared Statements and Callable Statements
SQL Statements
- Most of the actions you need to perform on a database are done with SQL statements.
- SQL keywords are NOT case sensitive: select is the same as SELECT.
- Some database systems require a semicolon at the end of each SQL statement.
- Semicolon is the standard way to separate each SQL statement in database systems that allow more than one SQL statement to be executed in the same call to the server.
- Here some important SQL statements
- SELECT - extracts data from a database
- UPDATE - updates data in a database
- DELETE - deletes data from a database
- INSERT INTO - inserts new data into a database
- CREATE DATABASE - creates a new database
- ALTER DATABASE - modifies a database
- CREATE TABLE - creates a new table
- ALTER TABLE - modifies a table
- DROP TABLE - deletes a table
- CREATE INDEX - creates an index (search key)
- DROP INDEX - deletes an index

Prepared Statements
- In database management systems, a prepared statement or parameterized statement is a feature used to execute the same or similar database statements repeatedly with high efficiency.
- As compared to executing statements directly, prepared statements offer two main advantages:
- The overhead of compiling the statement is incurred only once, although the statement is executed multiple times. However not all optimization can be performed at the time the statement template is compiled, for two reasons: the best plan may depend on the specific values of the parameters, and the best plan may change as tables and indexes change over time.
- Prepared statements are resilient against SQL injection because values which are transmitted later using a different protocol are not compiled like the statement template. If the statement template is not derived from external input, SQL injection cannot occur.
- On the other hand, if a query is executed only once, server-side prepared statements can be slower because of the additional round-trip to the server. Implementation limitations may also lead to performance penalties; for example, some versions of MySQL did not cache results of prepared queries. A stored procedure, which is also precompiled and stored on the server for later execution, has similar advantages. Unlike a stored procedure, a prepared statement is not normally written in a procedural language and cannot use or modify variables or use control flow structures, relying instead on the declarative database query language. Due to their simplicity and client-side emulation, prepared statements are more portable across vendors.
Callable Statement
- A CallableStatement object provides a way to call stored procedures in a standard way for all RDBMSs. A stored procedure is stored in a database; the call to the stored procedure is what a CallableStatement object contains. This call is written in an escape syntax that may take one of two forms: one form with a result parameter, and the other without one. A result parameter, a kind of OUT parameter, is the return value for the stored procedure. Both forms may have a variable number of parameters used for input (IN parameters), output (OUT parameters), or both (INOUT parameters). A question mark serves as a placeholder for a parameter.
- CallableStatement inherits Statement methods, which deal with SQL statements in general, and it also inherits PreparedStatement methods, which deal with IN parameters. All of the methods defined in CallableStatement deal with OUT parameters or the output aspect of INOUT parameters: registering the JDBC types of the OUT parameters, retrieving values from them, or checking whether a returned value was JDBC NULL. Whereas the getXXX methods defined in ResultSet retrieve values from a result set, the getXXX methods in CallableStatement retrieve values from the OUT parameters and/or return value of a stored procedure.
CallableStatementinheritsStatementmethods, which deal with SQL statements in general, and it also inheritsPreparedStatementmethods, which deal with IN parameters. All of the methods defined inCallableStatementdeal with OUT parameters or the output aspect of INOUT parameters: registering the JDBC types of the OUT parameters, retrieving values from them, or checking whether a returned value was JDBCNULL. Whereas thegetXXXmethods defined inResultSetretrieve values from a result set, thegetXXXmethods inCallableStatementretrieve values from the OUT parameters and/or return value of a stored procedure.
9. Need For ORM
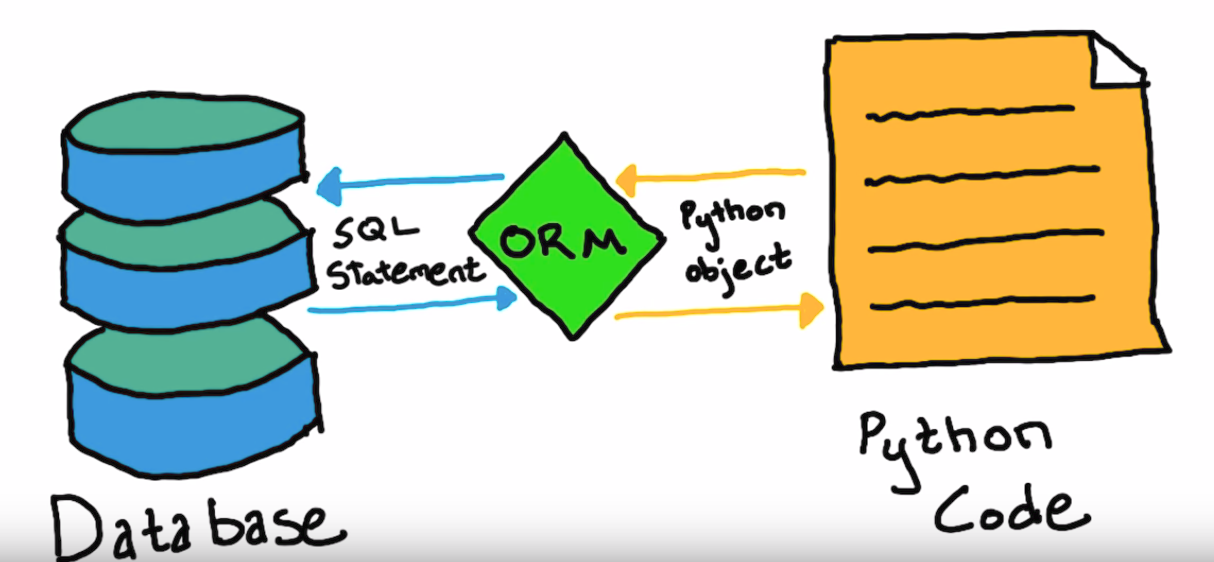
- An Object-Relational-Mapping tool basically takes away the pain (perceived) of writing SQL. As object-oriented programmers, we tend to think in terms of objects.
- An ORM tool keeps your object model separate from your persistence model, i.e., your java code need not know about your database tables. You write your data modification code in a programming language of your choice and the ORM tool will map that to the database for you.
- In most cases, you don’t have to write much SQL and you really don’t end up writing SQL that caters to a specific database vendor (in the highly unlikely case that you decide to switch databases after writing an application).
- ORMs also take away the repetitive, mind-numbing job of writing code that maps object properties to columns and vice-versa.
- The ORM debate isn’t about technology; it’s about values. People tell you that you should or shouldn’t use ORM based on what they think matters more: clean data access, or clean code.
- Here’s a list of ten reasons why you should consider an ORM tool. Now not all ORMs are created equal, but these are key features that a first class ORM will handle for you.
- Facilitates implementing the Domain Model pattern (Thanks Udi). This one reason supercedes all others. In short using this pattern means that you model entities based on real business concepts rather than based on your database structure. ORM tools provide this functionality through mapping between the logical business model and the physical storage model.
- Huge reduction in code. ORM tools provide a host of services thereby allowing developers to focus on the business logic of the application rather than repetitive CRUD (Create Read Update Delete) logic.
- Changes to the object model are made in one place. One you update your object definitions, the ORM will automatically use the updated structure for retrievals and updates. There are no SQL Update, Delete and Insert statements strewn throughout different layers of the application that need modification.
- Rich query capability. ORM tools provide an object oriented query language. This allows application developers to focus on the object model and not to have to be concerned with the database structure or SQL semantics. The ORM tool itself will translate the query language into the appropriate syntax for the database.
- Navigation. You can navigate object relationships transparently. Related objects are automatically loaded as needed. For example if you load a PO and you want to access it’s Customer, you can simply access PO.Customer and the ORM will take care of loading the data for you without any effort on your part.
- Data loads are completely configurable allowing you to load the data appropriate for each scenario. For example in one scenario you might want to load a list of POs without any of it’s child / related objects, while in other scenarious you can specify to load a PO, with all it’s child LineItems, etc.
- Concurrency support. Support for multiple users updating the same data simultaneously.
- Cache managment. Entities are cached in memory thereby reducing load on the database.
- Transaction management and Isolation. All object changes occur scoped to a transaction. The entire transaction can either be committed or rolled back. Multiple transactions can be active in memory in the same time, and each transactions changes are isolated form on another.
- Key Management. Identifiers and surrogate keys are automatically propogated and managed.
- In short, if you have a simple project with a none-too-complex object model, use simple JDBC. If you have a complex domain model with ‘interesting’ relationships between the objects, use an ORM.
10. POJO, Java Beans, and JPA
POJO
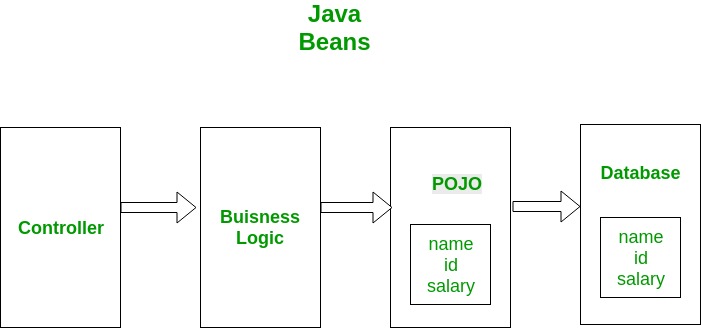
- POJO stands for Plain Old Java Object. It is an ordinary Java object, not bound by any special restriction other than those forced by the Java Language Specification and not requiring any class path. POJOs are used for increasing the readability and re-usability of a program. POJOs have gained most acceptance because they are easy to write and understand. They were introduced in EJB 3.0 by Sun microsystems.
- The term "POJO" initially denoted a Java object which does not follow any of the major Java object models, conventions, or frameworks; nowadays "POJO" may be used as an acronym for "Plain Old JavaScript Object" as well, in which case the term denotes a JavaScript object of similar pedigree.
- The term continues the pattern of older terms for technologies that do not use fancy new features, such as POTS (Plain Old Telephone Service) in telephony and Pod (Plain Old Documentation) in Perl. The equivalent to POJO on the .NET framework is Plain Old CLR Object (POCO). For PHP, it is Plain Old PHP Object (POPO).
- The POJO phenomenon has most likely gained widespread acceptance because of the need for a common and easily understood term that contrasts with complicated object frameworks.
Java Beans
- JavaBeans are classes that encapsulate many objects into a single object (the bean). It is a java class that should follow following conventions:
- Must implement Serializable.
- It should have a public no-arg constructor.
- All properties in java bean must be private with public getters and setter methods.
- According to Java white paper, it is a reusable software component. A bean encapsulates many objects into one object, so we can access this object from multiple places. Moreover, it provides the easy maintenance. In computing based on the Java Platform, JavaBeans are classes that encapsulate many objects into a single object (the bean). They are serializable, have a zero-argument constructor, and allow access to properties using getter and setter methods. The name "Bean" was given to encompass this standard, which aims to create reusable software components for Java. It is a reusable software component written in Java that can be manipulated visually in an application builder tool.
JPA
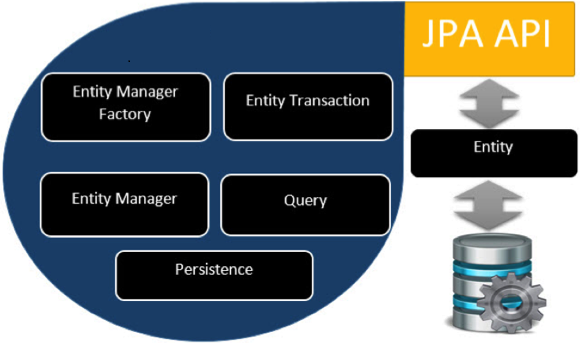
- The Java Persistence API (JPA) is a Java application programming interface specification that describes the management of relational data in applications using Java Platform, Standard Edition and Java Platform, Enterprise Edition.
- Java Persistence API is a collection of classes and methods to persistently store the vast amounts of data into a database. This tutorial provides you the basic understanding of Persistence (storing the copy of database object into temporary memory), and we will learn the understanding of JAVA Persistence API (JPA).
- A persistence entity is a lightweight Java class whose state is typically persisted to a table in a relational database. Instances of such an entity correspond to individual rows in the table. Entities typically have relationships with other entities, and these relationships are expressed through object/relational metadata. Object/relational metadata can be specified directly in the entity class file by using annotations, or in a separate XML descriptor file distributed with the application.
- Prior to the introduction of EJB 3.0 specification, many enterprise Java developers used lightweight persistent objects, provided by either persistence frameworks (for example Hibernate) or data access objects instead of entity beans. This is because entity beans, in previous EJB specifications, called for too much complicated code and heavy resource footprint, and they could be used only in Java EE application servers because of interconnections and dependencies in the source code between beans and DAO objects or persistence framework. Thus, many of the features originally presented in third-party persistence frameworks were incorporated into the Java Persistence API, and, as of 2006, projects like Hibernate (version 3.2) and TopLink Essentials have become themselves implementations of the Java Persistence API specification.
11. ORM Tools
Django
- Django's primary goal is to ease the creation of complex, database-driven websites. The framework emphasizes reusability and "pluggability" of components, less code, low coupling, rapid development, and the principle of don't repeat yourself. Python is used throughout, even for settings files and data models. Django also provides an optional administrative create, read, update and delete interface that is generated dynamically through introspection and configured via admin models.
- Django's configuration system allows third party code to be plugged into a regular project, provided that it follows the reusable app conventions. More than 2500 packages are available to extend the framework's original behavior, providing solutions to issues the original tool didn't tackle: registration, search, API provision and consumption, CMS, etc.
CakePHP
- CakePHP is an open-source web framework. It follows the model–view–controller (MVC) approach and is written in PHP, modeled after the concepts of Ruby on Rails, and distributed under the MIT License. CakePHP uses well-known software engineering concepts and software design patterns, such as convention over configuration, model–view–controller, active record, association data mapping, and front controller.
- CakePHP started in April 2005, when a Polish programmer Michal Tatarynowicz wrote a minimal version of a rapid application development in PHP, dubbing it Cake. He published the framework under the MIT license, and opened it up to the online community of developers. In December 2005, L. Masters and G. J. Woodworth founded the Cake Software Foundation to promote development related to CakePHP.[6] Version 1.0 was released on May 2006.
EBean
- Ebean is an object-relational mapping product written in Java. It is designed to be simpler to use and understand than JPA (Java Persistence API) or JDO (Java Data Objects) products. Ebean has a simpler API than JPA. It achieves this through its 'Session Less' architecture. Ebean does not require a JPA EntityManager or JDO PersistenceManager and this removes the concepts of detached/attached beans and the issues associated with flushing/clearing and 'session management' of EntityManagers. This adds up to make Ebean's API much easier to learn, understand and use.
- Although Ebean has full ORM features (equivalent to JPA) it also has incorporated 'SQL/Relational' features. The idea being that many development efforts require control over the exact sql, calling stored procedures or are more simply solved with 'Relational' approaches. The ultimate goal for Ebean is to combine the best ORM features from JPA with the best 'Relational' features from products like MyBatis into a single persistence framework.
Hibernate
- Hibernate ORM (Hibernate in short) is an object-relational mapping tool for the Java programming language. It provides a framework for mapping an object-oriented domain model to a relational database. Hibernate handles object-relational impedance mismatch problems by replacing direct, persistent database accesses with high-level object handling functions. Hibernate's primary feature is mapping from Java classes to database tables, and mapping from Java data types to SQL data types. Hibernate also provides data query and retrieval facilities. It generates SQL calls and relieves the developer from the manual handling and object conversion of the result set.
- Hibernate provides an SQL inspired language called Hibernate Query Language (HQL) for writing SQL-like queries against Hibernate's data objects. Criteria Queries are provided as an object-oriented alternative to HQL. Criteria Query is used to modify the objects and provide the restriction for the objects. HQL (Hibernate Query Language) is the object-oriented version of SQL. It generates database independent queries so that there is no need to write database-specific queries. Without this capability, changing the database would require individual SQL queries to be changed as well, leading to maintenance issues.
QuickDB ORM

- QuickDB ORM is an object-relational mapping framework for the Java software platform. It was developed by Diego Sarmentero along with others and is licensed under the LGPL License. Versions for .NET, Python and PHP are also being developed. QuickDB allows a developer to focus on the definition of the entities that represent the tables of the database and perform operations that allow the interaction between these entities and the database without having to perform tedious configurations, leaving to the library the task to infer the object structure and make the mapping of the object to the Database.
- QuickDB, like other tools for object-relational mapping, seeks to resolve the differences between the two co-existing data models: Object-Oriented Model and the Relational Model. To address this problem, it takes a fully object-oriented approach, where structures like "Objects composed of other objects", "Inheritance", "Collections" (one-to-many and many-to-many) are recognized by default as common entities, and also other features such as automatic table creation and modification of tables dynamically if the structure of the object change over time (addition of new attributes) are included. QuickDB not require the implementation of any interface, or the use of inheritance by the data model to be persistent, it is based simply on certain naming conventions for attributes to infer relevant information about the Object. However, it is possible to use annotations to set certain characteristics of the object, which gives the assurance that everything that QuickDB recognize by default, can be also managed completely by the developer. For queries, QuickDB pretends to maintain this approach where the developer works with the data model in a fully object-oriented way, and therefore the SQL statements (although they are permitted) are not necessary, and can be used by default a Query system where the condition to be evaluated is specified with a simple reference to the attributes in the objects from the data model.
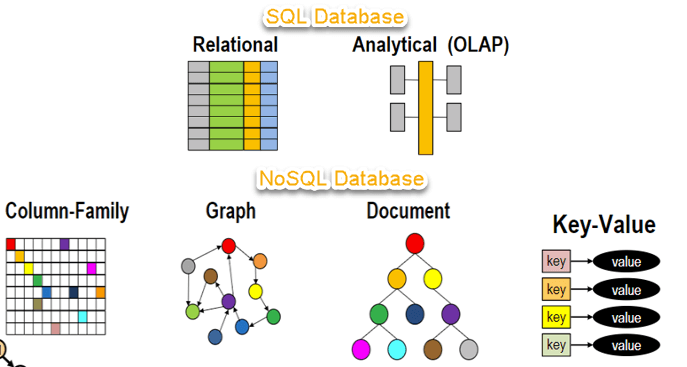
12. NoSQL
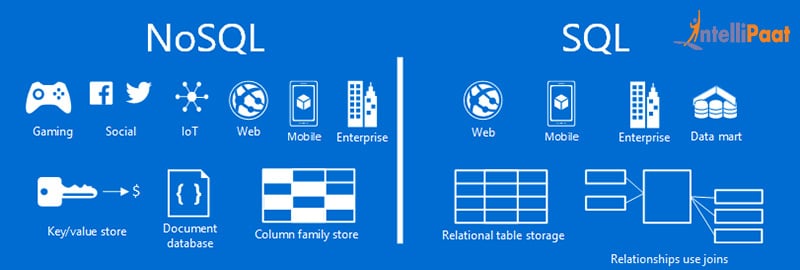
- Today, the advantages of NoSQL databases are no secret, especially when cloud computing has gained wide adoption. NoSQL databases were created in response to the limitations of traditional relational database technology. When compared against relational databases, NoSQL databases are more scalable and provide superior performance, and their data model addresses several shortcomings of the the relational model.
- NoSQL databases are not a direct replacement for an relational database management system (RDBMS). For many data problems, though, NoSQL is a better match than an RDBMS.
Advantages
➤ Support for unstructured text
- The vast majority of data in enterprise systems is unstructured. Many NoSQL databases can handle indexing of unstructured text either as a native feature (MarkLogic Server) or an integrated set of services including Solr or Elasticsearch.
- Being able to manage unstructured text greatly increases information and can help organizations make better decisions. For example, advanced uses include support for multiple languages with facetted search, snippet functionality, and word-stemming support. Advanced features also include support for dictionaries and thesauri.
- Furthermore, using search alert actions on data ingest, you can extract named entities from directories such as those listing people, places, and organizations, which allows text data to be better categorized, tagged, and searched.
- Entity enrichment services such as SmartLogic, OpenCalais, NetOwl, and TEMIS Luxid that combine extracted information with other information provide a rich interleaved information web and enhance efficient analysis and use.
➤ Ability to handle changeover time
- Because of the schema agnostic nature of NoSQL databases, they’re very capable of managing change — you don’t have to rewrite ETL routines if the XML message structure between systems changes.
- Some NoSQL databases take this a step further and provide a universal index for the structure, values, and text found in information. Microsoft DocumentDB and MarkLogic Server both provide this capability.
- If a document structure changes, these indexes allow organizations to use the information immediately, rather than having to wait for several months before you can test and rewrite systems.
➤ No reliance on SQL magic
- Structured Query Language (SQL) is the predominant language used to query relational database management systems. Being able to structure queries so that they perform well has over the years become a thorny art. Complex multitable joins are not easy to write from memory.
- Although several NoSQL databases support SQL access, they do so for compatibility with existing applications such as business intelligence (BI) tools. NoSQL databases support their own access languages that can interpret the data being stored, rather than require a relational model within the underlying database.
- This more developer-centric mentality to the design of databases and their access application programming interfaces (API) are the reason NoSQL databases have become very popular among application developers.
- Application developers don’t need to know the inner workings and vagaries of databases before using them. NoSQL databases empower developers to work on what is required in the applications instead of trying to force relational databases to do what is required.
➤ Breadth of functionality
- Most relational databases support the same features but in a slightly different way, so they are all similar.
- NoSQL databases, in contrast, come in four core types: key-value, columnar, document, and triple stores. Within these types, you can find a database to suit your particular (and peculiar!) needs. With so much choice, you’re bound to find a NoSQL database that will solve your application woes.
➤ Vendor choice
- The NoSQL industry is awash with databases, though many have been around for less than ten years. For example, IBM, Microsoft, and Oracle only recently dipped their toes into this market. Consequently, many vendors are targeting particular audiences with their own brew of innovation.
- Open‐]source variants are available for most NoSQL databases, which enables companies to explore and start using NoSQL databases at minimal risk. These companies can then take their new methods to a production platform by using enterprise offerings.
➤ No legacy code
- Because they are so new, NoSQL databases don’t have legacy code, which means they don’t need to provide support for old hardware platforms or keep strange and infrequently used functionality updated.
- NoSQL databases enjoy a quick pace in terms of development and maturation. New features are released all the time, and new and existing features are updated frequently (so NoSQL vendors don’t need to maintain a very large code base). In fact, new major releases occur annually rather than every three to five years.
➤ Executing code next to the data
- NoSQL databases were created in the era of Hadoop. Hadoop’s highly distributed filesystem (HDFS) and batch-processing environment (Map/Reduce) signaled changes in the way data is stored, queried, and processed.
- Queries and processing work now pass to several servers, which provides high levels of parallelization for both ingest and query workloads. Being able to calculate aggregations next to the data has also become the norm.
- You no longer need a separate data warehouse system that is updated overnight. With fast aggregations and query handling, analysis is passed to the database for execution next to the data, which means you don’t have to ship a lot of data around a network to achieve locally combined analysis.
Types of NoSQL databases
➤ Key value store NoSQL database

- The schema-less format of a key value database like Riak is just about what you need for your storage needs. The key can be synthetic or auto-generated while the value can be String, JSON, BLOB (basic large object) etc. The key value type basically, uses a hash table in which there exists a unique key and a pointer to a particular item of data. A bucket is a logical group of keys – but they don’t physically group the data. There can be identical keys in different buckets. Performance is enhanced to a great degree because of the cache mechanisms that accompany the mappings. To read a value you need to know both the key and the bucket because the real key is a hash (Bucket+ Key).
- There is no complexity around the Key Value Store database model as it can be implemented in a breeze. Not an ideal method if you are only looking to just update part of a value or query the database. When we try and reflect back on the CAP theorem, it becomes quite clear that key value stores are great around the Availability and Partition aspects but definitely lack in Consistency. While Key/value type database seems helpful in some cases, but it has some weaknesses as well. One, is that the model will not provide any kind of traditional database capabilities (such as atomicity of transactions, or consistency when multiple transactions are executed simultaneously). Such capabilities must be provided by the application itself.
➤ Document store NoSQL database
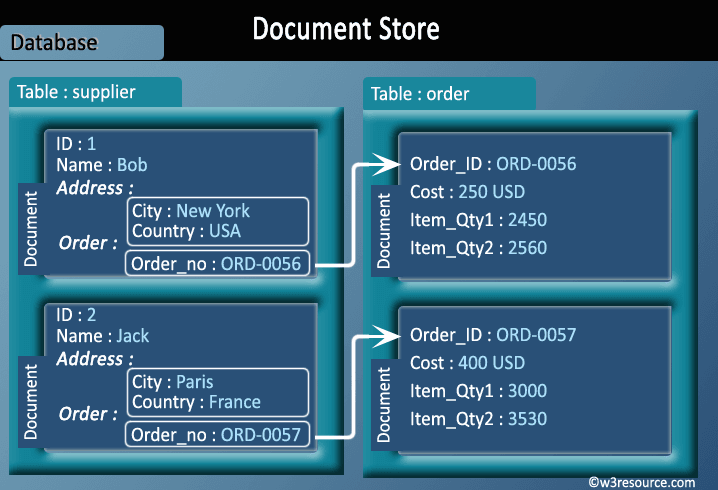
- The data which is a collection of key value pairs is compressed as a document store quite similar to a key-value store, but the only difference is that the values stored (referred to as “documents”) provide some structure and encoding of the managed data. XML, JSON (Java Script Object Notation), BSON (which is a binary encoding of JSON objects) are some common standard encodings.
➤ Column store NoSQL database
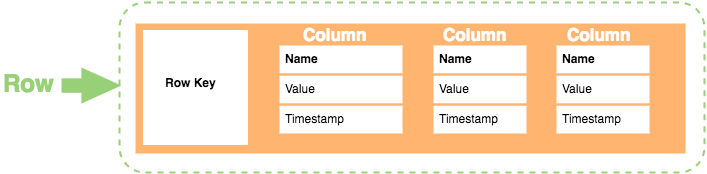
- In column-oriented NoSQL database, data is stored in cells grouped in columns of data rather than as rows of data. Columns are logically grouped into column families. Column families can contain a virtually unlimited number of columns that can be created at runtime or the definition of the schema. Read and write is done using columns rather than rows.
- In comparison, most relational DBMS store data in rows, the benefit of storing data in columns, is fast search/ access and data aggregation. Relational databases store a single row as a continuous disk entry. Different rows are stored in different places on disk while Columnar databases store all the cells corresponding to a column as a continuous disk entry thus makes the search/access faster.
➤ Graph Base NoSQL database

- In a Graph Base NoSQL Database, you will not find the rigid format of SQL or the tables and columns representation, a flexible graphical representation is instead used which is perfect to address scalability concerns. Graph structures are used with edges, nodes and properties which provides index-free adjacency. Data can be easily transformed from one model to the other using a Graph Base NoSQL database.
13. Hadoop

- The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
- The core of Apache Hadoop consists of a storage part, known as Hadoop Distributed File System (HDFS), and a processing part which is a MapReduce programming model. Hadoop splits files into large blocks and distributes them across nodes in a cluster. It then transfers packaged code into nodes to process the data in parallel. This approach takes advantage of data locality,[6] where nodes manipulate the data they have access to. This allows the dataset to be processed faster and more efficiently than it would be in a more conventional supercomputer architecture that relies on a parallel file system where computation and data are distributed via high-speed networking.
- Hadoop is an open source distributed processing framework that manages data processing and storage for big data applications running in clustered systems. It is at the center of a growing ecosystem of big data technologies that are primarily used to support advanced analytics initiatives, including predictive analytics, data mining and machine learning applications. Hadoop can handle various forms of structured and unstructured data, giving users more flexibility for collecting, processing and analyzing data than relational databases and data warehouses provide.
Core Concepts
➤ MapReduce
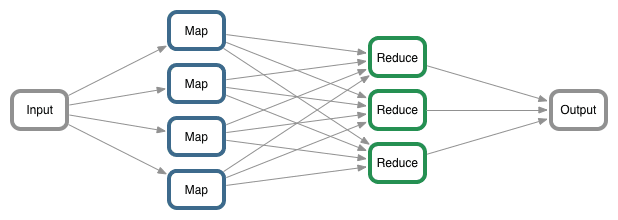
- MapReduce is a programming model for parallel processing of large volumes of data in a distributed environment. The MapReduce paradigm has two main components, one is the Map() method, which performs filtering and sorting. The other one is the Reduce() part, designed to perform summary of the output from the Map part.
➤ Hadoop Common
- Apache Common contains common utilities to support different Hadoop modules. It is basically a library of common tools and utilities. Hadoop common is mainly used by developers during application development.

➤ Hadoop distributed file system
- The Hadoop Distributed File System (HDFS) is a distributed file system spans across commodity hardware. It scales very fast and provides high throughput. Data blocks are replicated and stored in a distributed way on a clustered environment.
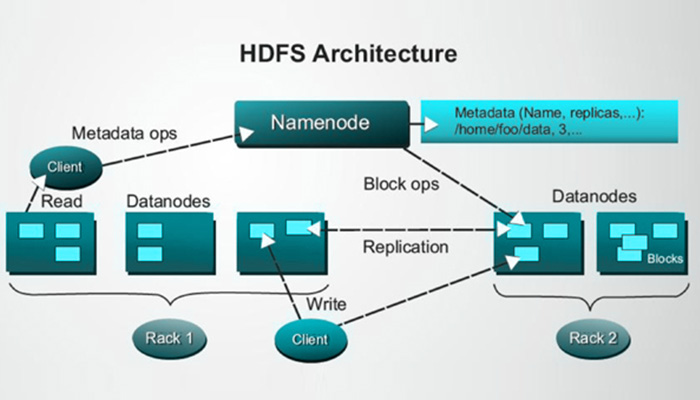
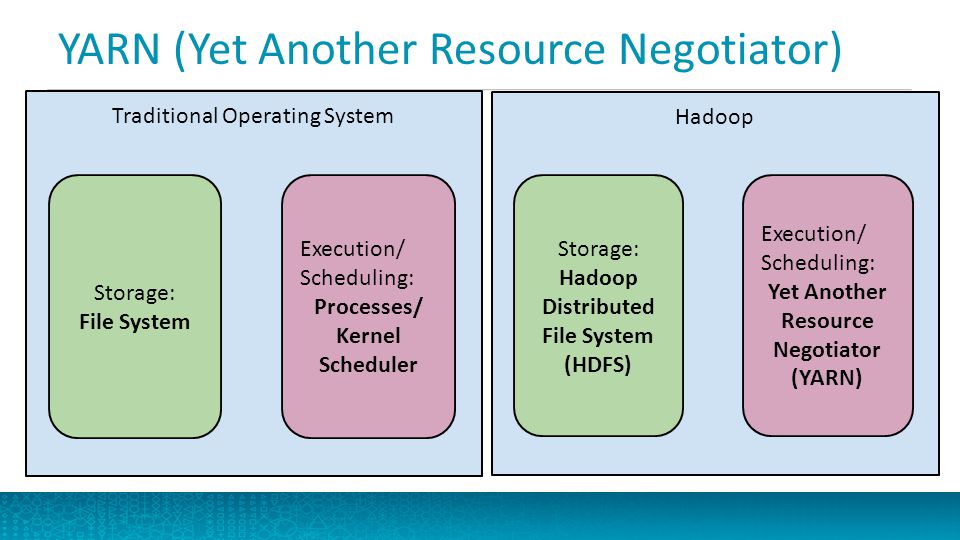
➤ YARN
- Yet Another Resource Negotiator (YARN) is a resource manager available in Hadoop 2. The role of YARN is to manage and schedule computing resources in a clustered environment.
14. Information Retrieval
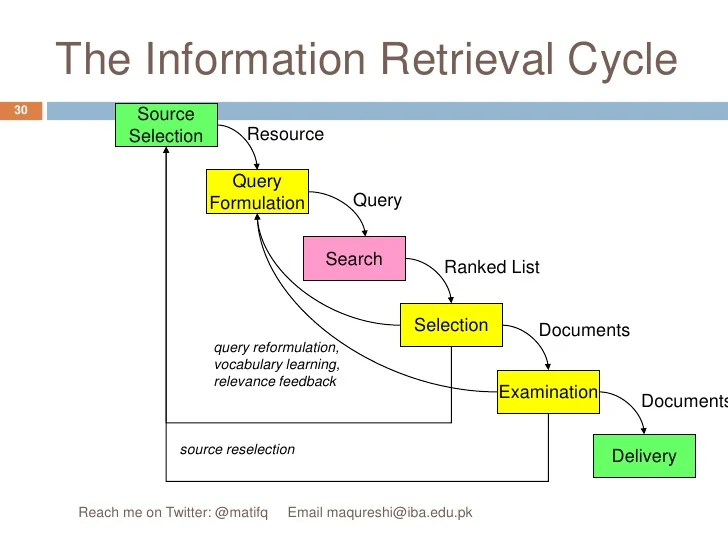
- Information Retrieval is the activity of obtaining information system resources relevant to an information need from a collection. Searches can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for metadata that describe data, and for databases of texts, images or sounds.
- Automated information retrieval systems are used to reduce what has been called information overload. An IR system is a software that provide access to books, journals and other documents, stores them and manages the document. Web search engines are the most visible IR applications.
Concept
- Information retrieval and information filtering are different functions. Information retrieval is intended to support people who are actively seeking or searching for information, as in Internet searching. Information retrieval typically assumes a static or relatively static database against which people search. Search engine companies construct these databases by sending out “spiders” and then indexing the Web pages they find. By contrast, information filtering supports people in the passive monitoring for desired information. It is typically understood to be concerned with an active incoming stream of information objects.
- The problem in information retrieval and information filtering is that decisions must be made for every document or information object regarding whether or not to show it to the person who is retrieving the information. Initially, a profile describing the user’s information needs is set up to facilitate such decision making; this profile may be modified over the long term through the use of user models. These models are based on a person’s behavior—decisions, reading behaviors, and so on, which may change the original profile. Both information retrieval and information filtering attempt to maximize the good material that a person sees (that which is likely to be appropriate to the information problem at hand) and minimize the bad material.
- Most search engines designed for the World Wide Web use the principle of “best match,” that is, not making yes/no decisions but, rather, ranking information objects with respect to some representation of the information problem. Thus, the basic processes in information retrieval or information filtering are the representations of information objects and of information needs, or more generally, the problem or goal that the person has in mind. The retrieval techniques themselves then compare needs with objects.
- The interaction of the user with other components of the system is important. In fact, the prevailing view in information retrieval research is that the most effective approach for helping a user obtain the appropriate information is relevance feedback, in which the system takes into account whether a person likes or dislikes a document as it automatically re-represents the user’s query. This leads to performance improvements of as much as 150 percent—much better than any other technique. Thus, the person’s judgment of the information objects is an important part of the process. The user is an actor in the information retrieval system, because many of the processes depend on his or her expression and interpretation of the need. The relevance of a document cannot be determined unless the person is considered a part of the system.
- The second important part of the system is the information resource, a collection of information objects that has been selected, organized, and represented according to some schema. The third component is the intermediary—a device or person that mediates between the information resource and the user and that has knowledge of the user, the user’s problem, and the types of users that exist, as well as the information resource, the way the resource is organized, what it contains, and so on. The intermediary supports the interaction between people and the information objects and knowledge resource, through prediction and other means.

No comments:
Post a Comment