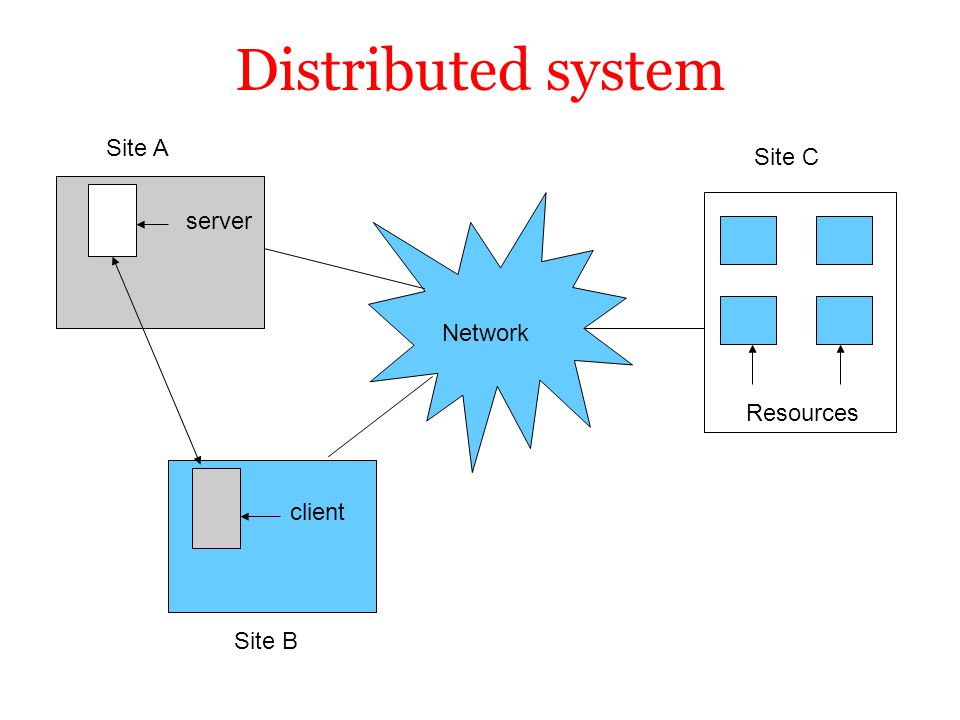
1. Distributed Systems

- A distributed system is a network that consists of autonomous computers that are connected using a distribution middleware.
- They help in sharing different resources and capabilities to provide users with a single and integrated coherent network.
Let's see the advantages!!
Speed and content distribution
- Distributed systems can also be faster than single-computer systems.
- One of the advantages of a distributed database is that queries can be routed to a server with a particular user's information, rather than all requests having to go to a single machine that can be overloaded.
- Requests can also be routed to servers physically close or on a speedy network connection to whoever wants the data, which can mean less time and other resources allocated to dealing with network traffic and bottlenecks.
- That's a common occurrence in content distribution networks used for online media.
Scaling
- Once distributed systems are set up to distribute data among the servers involved, they can also be easily scalable.
- If they're well designed, it can be as simple as adding some new hardware and telling the network to add it to the distributed system.
Parallelism
- Distributed systems can also be designed for parallelism.
- This is common in mathematical operations for things like weather modeling and scientific computing, where multiple powerful processors can divide up independent parts of complex simulations and get the answer faster than they would be running them in series.
Redundancy
- Several machines can provide the same services, so if one is unavailable, work does not stop.
- Additionally, because many smaller machines can be used, this redundancy does not need to be prohibitively expensive.
1.1 Distributed Computing

- Distributed computing is a model in which components of a software system are shared among multiple computers to improve efficiency and performance.
- According to the narrowest of definitions, distributed computing is limited to programs with components shared among computers within a limited geographic area.
- Broader definitions include shared tasks as well as program components.
What is the difference between Distributed Systems and Distributed Computing?
Distributed Systems |
Distributed Computing |
|---|---|
|
|
|
|
|
|
2. Standalone Systems

- A standalone device is any mechanism or system that can perform its function without the need for another device, computer, or connection. A perfect sample of a standalone device is a copy or fax machine, as shown in the picture.
What are the advantages?
- One advantage of a standalone computer is damage control.
- For example, if something goes wrong, only the standalone will be affected.
- Simplicity is another advantage because it takes a lot less expertise to manage one computer than it does to set up or troubleshoot several.
- Standalone computers can also be more convenient.
- For example, printing on a network may require you to walk some distance from the computer to the printer. Inversely, any peripherals on a standalone have to be in arm's reach.
- Finally, a standalone does not affect other computer users.
- With a network, one user may waste space by watching movies or listening to music.
- In turn, everyone else using the network may see slower computer performance.
- Cheaper hardware and software (wires, network cards, and software for the network are expensive)
- Less IT knowledge needed (no need for a network administrator/difficult to run a successful network)
- Fewer problems with viruses.
- Less dependence on hardware (i.e. in a network, if the file server is down, the whole network has issues)
Standalone Systems vs Distributed Systems
| Standalone Systems | Distributed Systems |
|---|---|
|
|
|
|
|
|
|
|
|
|
3. Elements of Distributed System
Operational Platform
- At the very base of the system, you need to have networking gear, servers, the means to put operating systems onto the servers, bring them up to the baseline configuration, and monitor their operational status (disk, memory, CPU, etc).
- There are lots of good tools here. Getting the initial bits onto disk will usually be determined by the operating system you are using, but after that Chef or Puppet should become your friend.
- You’ll use these to know what is out there and bring servers up to a baseline.
- We personally believe that chef or puppet should be used to handle things like accounts, DNS, and stable things common to a small number of classes of a server (app server, database server, etc).
- The operational platform provides the raw material on which the system will run, and the tools here are chosen to manage that raw material.
- This is different than application management.
Deployment
- The first part of application management is a means of getting application components onto servers and controlling them.
- It is generally preferred deploying complete, singular packages which bundle up all their volatile dependencies.
- Think hard about how development, debugging, and general work with these things will go, as being pleasant to work with during dev, test, and downtime will trump idealism in production.
Configuration
- Your configuration system is going to be intimately tied to your deployment system, so think about these things together.
- The immutable configuration obtained at startup or deployment time.
- A new set of configs means a restart. In this case, you can either have the deployment system provide it to the application, or have the application itself fetch it.
- Some folks really like dynamic configuration, in that case, Zookeeper is going to be your friend.
Application Monitoring
- Application level monitoring and operational level monitoring are very similar, and can frequently be combined in one tool, but are conceptually quite different.
- For one thing, operational monitoring is usually available out of the box from good old Nagios to newer tools like ‘noit.
- Generally, you will want to track the same kinds of things, but how you get it, and what they mean will vary by the application.
4. Types of Services Gained From Distributed Systems
Centralized Model

- As shown in the figure above in which there is no networking.
- All aspects of the application are hosted on one machine and users directly can connect to the central machine.
- The computer may contain one or more CPUs and users communicate with it via terminals that have a direct (e.g., serial) connection to it.
- The main problem with the centralized model is that it is not easily scalable.
- There is a limit to the number of CPUs in a system and eventually, the entire system needs to be upgraded or replaced.
Client-server model

- The client-server model is a popular networked model consisting of the three following elements.
- Service is a task that a particular machine can perform. For example, offering files over a network, the ability to execute certain commands, or routing data to a printer.
- A server is the machine that performs the task (the machine that hosts the service). A machine that is primarily recognized for the service it provides is often referred to as a print server, file server, et al.
- A client is a machine that is requesting the service.
- The client can be either thin or thick client.
- Thin client is designed around the premise that the amount of client software should be small and the bulk of processing takes place on the servers. Because the software requirements are minimal, less hardware is needed to run the software. Examples of thin clients are an X terminal or Web Browser-based websites. With thin clients, there is no need for much administration, expansion slots, CDs, or even disks. The thin client can be considered to be an information appliance (wireless device, or set-top box) that only needs connectivity to resource-rich networking.
- Thick client (or fat client ) performs the bulk of data processing operations. A server may perform rather rudimentary or simple tasks such as storing and retrieving data.
Multi-tier Architecture

- In software engineering, multi-tier architecture (often referred to as n-tier architecture) is a client–server architecture in which presentation, application processing, and data management functions are logically separated.
- The most widespread use of multi-tier architecture is the three-tier architecture.
- N-tier application architecture provides a model by which developers can create flexible and reusable applications.
- By segregating an application into tiers, developers acquire the option of modifying or adding a specific layer, instead of reworking the entire application.
- A Three-tier architecture is typically composed of a presentation tier, a business or data access tier, and a data tier.
Peer to peer model

- A peer-to-peer (P2P) network is a type of decentralized and distributed network architecture in which individual nodes in the network (called “peers”) act as both suppliers and consumers of resources, in contrast to the centralized client-server model where client nodes request access to resources provided by central servers. In a peer-to-peer network, tasks (such as searching for files or streaming audio/video) are shared amongst multiple interconnected peers who each make a portion of their resources (such as processing power, disk storage or network bandwidth) directly available to other network participants, without the need for centralized coordination by servers.
5. Browser-Based and Non-Browser-Based Clients of Distributed Systems
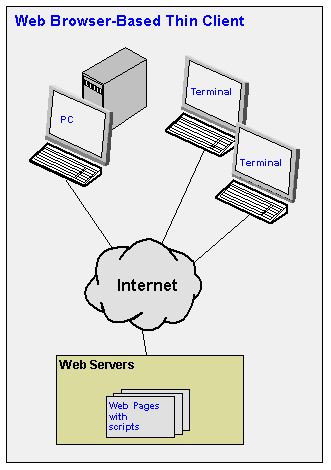
- Many companies assume that developing business applications "inside the browser" is their only option.
- While browsers provide an excellent, fast way to deploy simple applications, for more complex business application needs, a browser-based approach is very expensive, and often falls short of usability needs.
- Smart Client applications provide a much richer End User experience, they are much less expensive to develop and maintain, and they overcome many common limitations for using the Internet for B2B data management needs.
- Given the simplicity of programming basic web functionality, it is entirely practical to write your own HTTP clients for specific uses.
- Currently, the most popular non-browser web clients are robots that index the Web for search engines and link checkers that find broken links, but there is an infinite number of possible client programs and devices.
non- browser client = anything that's not a browser that goes online
- We develop our web pages serving HTML along with javascript and CSS that get executed on a browser.
- If you look inside, here browser requests the data over HTTP and web servers deliver it.
- There can be other methods of requesting data over HTTP like wget, curl.
- They are called non-browser clients.
- The web server will equally respond to them.
- It is widely used for Crawling and Web Services.
6. Characteristics of Different Types of Web-based Systems

Rich Internet Applications

- RIAs are web applications that have most of the characteristics of desktop applications, typically delivered through web-browser plug-ins or independently via sandboxes or virtual machines.
- RIAs have always been about the user experience, it enhancing the end-user experience in different ways.
- RIAs can run faster and be more engaging. They can offer users a better visual experience, better accessibility, usability, and more interactivity than traditional browser applications that use only HTML and HTTP.
- A RIA can perform computation on both the client side and server side. User Interface, its related activity, and capability on the client side and the data manipulation and operation on the application server side.
- RIA is developed using various technologies such as Java, Silverlight, JavaFX, JavaScript, REST/WS etc.
Let's look at some characteristics
Performance
- RIAs can often perform better than traditional applications on the basis of the characteristics of network and applications, the performance of server also improved by offloading possible processing work to the client system and also perceived performance in terms of UI responsiveness and smoother visual transitions and animations are key aspects of any RIA.
Offline use
- When connectivity is unavailable, it might still be possible to use an RIA. An RIA platform let the user work with the application without connecting to the Internet and synchronizing it automatically when the user goes live.
Security
- RIAs should be as secure as any other web application, and the framework should be well equipped to enforce limitations appropriately when the user lacks the required privileges, especially when running within a constrained environment such as a sandbox.
Direct interaction
- An RIA can use a wider range of controls that allow greater efficiency and enhance the user experience. In RIAs, for example, users can interact directly with page elements through editing or drag-and-drop tools. They can also do things like pan across a map or other image.
Improved features
- RIA allow programmers to embed various functionalities in graphics-based web pages that look fascinating and engaging like desktop applications.
- RIA provides complex application screens on which various mixed media, including different fonts, vector graphic and bitmap files online conferencing etc. are paused by using different modern development tools.
Better feedback
- Because of their ability to change parts of pages without reloading, RIAs can provide the user with fast and accurate feedback, real-time confirmation of actions and choices, and informative and detailed error messages.
Now let's have a look at different types of web based-systems
Document-Centric Web Applications

- Document-centric web sites are static HTML documents stored on a web server that is sent directly to the client on request.
- The web pages are manually updated with the help of respective tools.
- These applications are static, simple, stable and take less time to respond.
- These applications are costly to maintain (at the time of update), having inconsistency problem because of being static, no timely update of information.
Transactional web-based applications
- These kinds of web applications have the facility of modification by the user.
- These applications are more interactive and support structured queries from the database.
- The database system handles data consistently and efficiently.
Ubiquitous web application
- These kinds of applications provide customized facilities for any device from anywhere at any time.
- It has limited interaction facility and supports limited device.
- It requires advanced knowledge of context where the web application is being used for dynamic adjustment.
- Services based on location is an example of such a web application.
Collaborative web application
- These kinds of applications are mainly used as group applications where group communications are an important part.
- Chat rooms, online forums, e-learning websites or websites where information are shared with the option of editing like Wikipedia are some examples of such web application.
7. Different Architectures for Distributed Systems
Layered Architecture

- The layered architecture separates layers of components from each other, giving it a much more modular approach.
- A well known example for this is the OSI model that incorporates a layered architecture when interacting with each of the components.
- Each interaction is sequential where a layer will contact the adjacent layer and this process continues, until the request is been catered to.
- But in certain cases, the implementation can be made so that some layers will be skipped, which is called cross-layer coordination.
- Through cross-layer coordination, one can obtain better results due to performance increase.
- The layers on the bottom provide a service to the layers on the top.
- The request flows from top to bottom, whereas the response is sent from bottom to top.
- The advantage of using this approach is that, the calls always follow a predefined path, and that each layer can be easily replaced or modified without affecting the entire architecture.
- The above image is the basic idea of a layered architecture style.
Object Based Architecture

- This architecture style is based on loosely coupled arrangement of objects.
- This has no specific architecture like layers.
- Like in layers, this does not have a sequential set of steps that needs to be carried out for a given call.
- Each of the components are referred to as objects, where each object can interact with other objects through a given connector or interface.
- These are much more direct where all the different components can interact directly with other components through a direct method call.
- As shown in the above image, communication between object happen as method invocations. These are generally called Remote Procedure Calls (RPC).
Data Centered Architecture

- As the title suggests, this architecture is based on a data center, where the primary communication happens via a central data repository.
- This common repository can be either active or passive.
- This is more like a producer consumer problem. The producers produce items to a common data store, and the consumers can request data from it.
- This common repository, could even be a simple database.
- But the idea is that, the communication between objects happening through this shared common storage.
- This supports different components (or objects) by providing a persistent storage space for those components (such as a MySQL database).
- All the information related to the nodes in the system are stored in this persistent storage.
- In event-based architectures, data is only sent and received by those components who have already subscribed.
- Some popular examples are distributed file systems, producer consumer, and web based data services.
Event Based Architecture

- The entire communication in this kind of a system happens through events.
- When an event is generated, it will be sent to the bus system.
- With this, everyone else will be notified telling that such an event has occurred.
- So, if anyone is interested, that node can pull the event from the bus and use it.
- Sometimes these events could be data, or even URLs to resources.
- So the receiver can access whatever the information is given in the event and process accordingly. processes communicate through the propagation of events.
- These events occasionally carry data.
- An advantage in this architectural style is that, components are loosely coupled.
- So it is easy to add, remove and modify components in the system.
- Some examples are, publisher - subscriber system, Enterprise Services Bus (ESB) and akka.io.
- One major advantage is that, these heterogeneous components can contact the bus, through any communication protocol.
- But an ESB or a specific bus, has the capability to handle any type of incoming request and process accordingly.
- This architectural style is based on the publisher-subscriber architecture.
- Between each node there is no direct communication or coordination.
- Instead, objects which are subscribed to the service communicate through the event bus.
Client Server Architecture

- The client server architecture has two major components.
- The client and the server. The Server is where all the processing, computing and data handling is happening, whereas the Client is where the user can access the services and resources given by the Server (Remote Server).
- The clients can make requests from the Server, and the Server will respond accordingly.
- Generally, there is only one server that handles the remote side.
- But to be on the safe side, we do use multiple servers will load balancing techniques.
- As one common design feature, the Client Server architecture has a centralized security database.
- This database contains security details like credentials and access details.
- Users can't log in to a server, without the security credentials.
- So, it makes this architecture a bit more stable and secure than Peer to Peer.
- The stability comes where the security database can allow resource usage in a much more meaningful way.
- But on the other hand, the system might get low, as the server only can handle a limited amount of workload at a given time.
Peer To Peer

- The general idea behind peer to peer is where there is no central control in a distributed system.
- The basic idea is that, each node can either be a client or a server at a given time.
- If the node is requesting something, it can be known as a client, and if some node is providing something, it can be known as a server.
- In general, each node is referred to as a Peer.
- In this network, any new node has to first join the network.
- After joining in, they can either request a service or provide a service.
- The initiation phase of a node (Joining of a node), can vary according to implementation of a network.
- There are two ways in how a new node can get to know, what other nodes are providing.
8. Micro-Service Architecture vs Monolithic Architecture
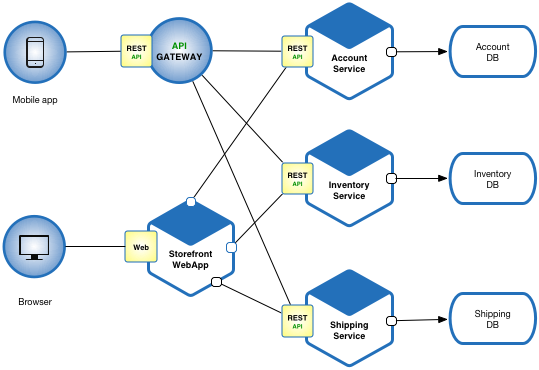
- Microservices - also known as the microservice architecture - is an architectural style that structures an application as a collection of services that are
- Highly maintainable and testable
- Loosely coupled
- Independently deployable
- Organized around business capabilities.
- The microservice architecture enables the continuous delivery/deployment of large, complex applications.
- It also enables an organization to evolve its technology stack.

- Monolith means composed all in one piece.
- The Monolithic application describes a single tiered software application in which different components combined into a single program from a single platform.
- Consider an example of Ecommerce application, that authorizes customer, takes an order, check products inventory, authorize payment and ships ordered products. This application consists of several components including e-Store User interface for customers (Store web view) along with some backend services to check products inventory, authorize and charge payments and shipping orders.
Now let’s discuss the differences of each, point by point.
Deployment
- Monolith apps allow you to set your deployment once and then simply adjust it based on ongoing changes. At the same time, however, there is also only a single point of failure during deployment and, if everything goes wrong, you could break your entire project.
- Microservices require much more work; you will need to deploy each microservice independently, worry about orchestration tools, and try to unify the format of your ci/cd pipelines to reduce the a amount of time required for doing it for each new microservice. There is a bright side, however; if something goes wrong, you will only break one small microservice, which is less problematic than the entire project. It’s also much easier to rollback one small microservices than and entire monolith app.
Maintenance
- If you plan to use a microservices architecture, get a DevOps for your team and prepare yourself. Not every developer will be familiar with Docker or orchestration tools, such as Kubernetes, Docker Swarm, Mesosphere, or any similar tool that could help you to manage infrastructure with a lot of moving parts. Someone has to monitor and maintain the functioning state of your CI configuration for each microservice and the whole infrastructure.
Reliability
- Microservices architecture is the obvious winner here. Breaking one microservice affects only one part and causes issues for the clients that use it, but no one else. If, for example, you’re building a banking app and the microservice responsible for money withdrawal is down, this is definitely less serious than the whole app being forced to stop.
Scalability
- For scalability, microservices are again better suited. Monolith apps are hard to scale because, even if you run more workers, every worker will be on the single, whole project, an inefficient way of using resources. Worse, you may write your code in the way that would render it impossible to scale it horizontally, leaving only vertical scaling possible for your monolith app. With microservices, this is much easier. Resources can be used more carefully and allow you to scale only that parts that require more resources.
Cost
- Cost is tricky to calculate because monolith architecture is cheaper in some scenarios, but not in others. For example, with the better scalability of microservices, you could set up an auto-scale and only pay for that when the volume of users really requires more resources. At the same time, to keep that infrastructure up and running you need a devops that needs to be paid. With a small monolith app, you could run on a $5-$20 host and turn on the snapshot. With a larger monolith app, you may host a very expensive instance because you can’t share it over multiple small, cheap hosts.
Releasing
- Microservices that are smaller and with a proper architecture of microservices communication allow you to release new features faster by reducing QA time, build time, and tests execution time. Monolith apps have a lot of internal dependencies that could not be broken up. There is also a higher risk that something you are committed to could depend on unfinished changes from your team members, which could potentially postpone releases.
9. MVC Style
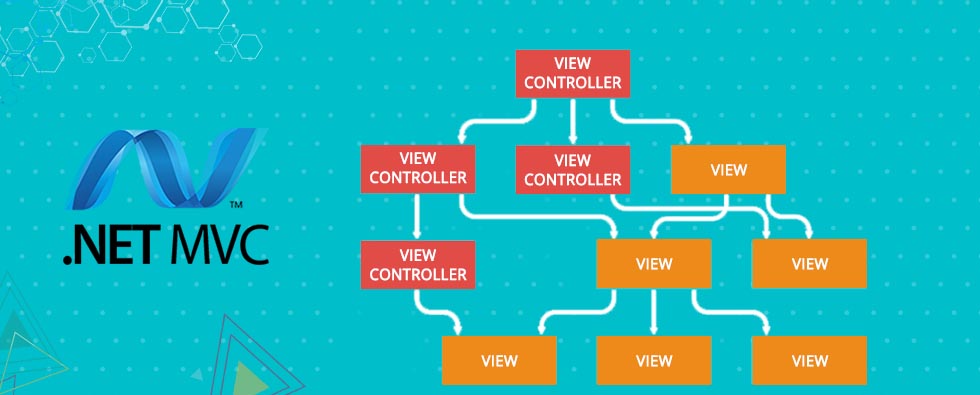
- Model-View-Controller (usually known as MVC or Model WC for the MVVC variant) is an architectural pattern commonly used for developing user interfaces that divides an application into three interconnected parts. This is done to separate internal representations of information from the ways information is presented to and accepted from the user. The MVC design pattern decouples these major components allowing for efficient code reuse and parallel development.
- Traditionally used for desktop graphical user interfaces (GUIs), this architecture has become popular for designing web applications and even mobile, desktop and other clients. Popular programming languages like Java, C#, Python, Ruby, PHP have MVC frameworks that are used in web application development straight out of the box.
Model
- The central component of the pattern. It is the application's dynamic data structure, independent of the user interface. It directly manages the data, logic and rules of the application.
View
- Any representation of information such as a chart, diagram or table. Multiple views of the same information are possible, such as a bar chart for management and a tabular view for accountants.
Controller
- Accepts input and converts it to commands for the model or view.
Use in web application
- Although originally developed for desktop computing, MVC has been widely adopted as an architecture for World Wide Web applications in major programming languages. Several web frameworks have been created that enforce the pattern. These software frameworks vary in their interpretations, mainly in the way that the MVC responsibilities are divided between the client and server.
- Some web MVC frameworks take a thin client approach that places almost the entire model, view and controller logic on the server. This is reflected in frameworks such as Django, Rails and ASP.NET MVC. In this approach, the client sends either hyperlink requests or form submissions to the controller and then receives a complete and updated web page (or other document) from the view; the model exists entirely on the server. Other frameworks such as AngularJS, EmberJS, JavaScriptMVC and Backbone allow the MVC components to execute partly on the client (also see Ajax).
10. Different Approaches of Use of MVC For Web-based Systems

- Over the years, software development has gone through many changes.
- One of the biggest change that happened in the recent years, is the use of MVC pattern for developing software or web application.
- The Model–view–controller shortly known as MVC is a software architectural design for implementing user interfaces on computers.
- The MVC pattern is a great architecture no matter whatever the language you are using for the development.
- MVC patterns separate input, processing, and output of an application.
- This model divided into three interconnected parts called the model, the view, and the controller.
- All of the three above given components are built to handle some specific development aspects of any web or software application.
- In the MVC development, controller receives all requests for the application and then instruct the model to prepare any information required by the view.
- The view uses that data prepared by the controller to bring the final output.
What are the strengths?
Faster development process
- MVC supports rapid and parallel development.
- If an MVC model is used to develop any particular web application then it is possible that one programmer can work on the view while the another can work on the controller to create business logic of the web application.
- Hence this way, the application developed using MVC model can be completed three times faster than applications that are developed using other development pattern.
Ability to provide multiple views
- In the MVC Model, you can create multiple views for a model.
- Today, there is an increasing demand for new ways to access your application and for that MVC development is certainly a great solution.
- Moreover, in this method, Code duplication is very limited because it separates data and business logic from the display.
Support for asynchronous technique
- The MVC architecture can also integrate with the JavaScript Framework.
- This means that MVC applications can be made to work even with PDF files, site-specific browsers, and also with desktop widgets.
- MVC also supports asynchronous technique, which helps developers to develop an application that loads very fast.
The modification does not affect the entire model
- For any web application, user interface tends to change more frequently than even the business rules of the company.
- It is obvious that you make frequent changes in your web application like changing colors, fonts, screen layouts, and adding new device support for mobile phones or tablets.
- Moreover, Adding new type of views are very easy in MVC pattern because the Model part does not depend on the views part.
- Therefore, any changes in the Model will not affect the entire architecture.
MVC model returns the data without formatting
- MVC pattern returns data without applying any formatting.
- Hence, the same components can be used and called for use with any interface.
- For example, any kind of data can be formatted with HTML, but it could also be formatted with Macromedia Flash or Dream viewer.
What are the weaknesses?
- Increased complexity
- Inefficiency of data access in view
- Difficulty of using MVC with modern user interface.
- Need multiple programmers
- Knowledge on multiple technologies is required.
- Developer have knowledge of client side code and html code.
11. The Need For Very Specific Type of Communication Technologies For The Distributed/Web-Based Systems
Extensible Markup Language(XML)

- To have an electronic communication it should be used a standard trough it the information can be transmitted or received, plus it should be understood by both parties and systems involved in communication.
- This need has led to the definition of SGML (Standard Generalized Markup Language).
- This standard is based on so-called markers, used to delimit the beginning and end information. SGML standard was used for a long time (more than 15 years) by large firms in very specific applications.
- Along with the development of web technologies is required the use of a similar standard, but to be more accessible and also to preserve its original standard in describing fully the information contained.
- This is the definition of XML as a derived standard from SGML as it is not belonging to any company and it is an open standard used on any platform and for any type of data transmission, preferable to implement web services.
Resource Description Framework (RDF)

- Resource Description Framework (RDF), defined of W3C, is a XML text format that supports resource description and metadata applications such as camera or photo collections.
- For example, RDF can allow people identification in a photo album (for web) using information from a contact list; then mail client could automatically send an email to these people, alerting them that their photos are on the web (on-line).
- Such as HTML integrated documents, images, menu systems and forms, RDF are a tool that allows a deeper integration to transform the Web to becoming a semantic web.
- Just as people need a convention to determine the meanings of words also and computers need the same thing to communicate efficient. Formal descriptions of a certain category (for example purchase or production) are called ontology and are a necessary part of the Semantic Web. RDF, ontology and representation enable computers to help people work; these are a part of the Semantic Web Activity.
Web Services Description Language (WSDL)

- WSDL is an interface that describes in detail the functions that provide a web service.
- In other words, the WSDL is a description of functions that are provided by SOAP servers starting from the indicated UDDI.
- WSDL can be seen as an XML document that describes the routines used in applications, describes the web server location, data form that are received from the communication routines and used parameters.
- Using a WSDL document can automatically generate classes to access web service.
- In this way the programmer is relieved from the duty to write these classes manually.
- A WSDL file is an XML document that describes a Web service using the six main elements:
- Port type - groups and describes operations that are performed by service
- The port - specify an address for a combination, for example defines a communication port
- The message - describing the names and formats supported by service
- Types - defines data types (such as were defined in XML schema) used by the service for sending messages between client and server.
- The joint - defines the communication protocols supported by the operations that provide services
- The service - specific URL address to access the service.
- WSDL document describing a Web service acts as a contract between client and server web service.
- By adhering to this contract, the service provider and consumer can exchange data in a standardized way regardless of application and platform that operates.
Simple Object Access Protocol (SOAP)

- To use a web service is necessary to use a way of data "packing" organized in the form of XML's, to facilitate reading and interpretation by the web server.
- In this way appeared SOAP (Simple Object Access Protocol) standard that can be viewed as an envelope, containing information.
- The media does not change from XML, and binary format is unconverted.
- Are avoided past issues of inconsistency between different operating systems and platforms used.
- SOAP is an XML-based protocol defined by the W3C for exchanging data over HTTP, being a simple and standardized method for sending XML messages between applications.
- Web services use SOAP to send messages between a service and its client/clients.
- Because all browsers and Web services support HTTP, SOAP messages can be transmitted between applications regardless of platform or programming language.
- This quality provides web services their interoperability feature.
- SOAP messages are XML documents that contain some or all of the following:
- The envelope - which specifies that the XML document is a SOAP message that contains the message itself
- Header (optional) - contains relevant information related message, such as the date on which the message was sent on authentication, etc.
- Content - including message
- Error - carries information about an error occurred on the server or client level in a SOAP message
- Dates are sent between the client (clients) and Web service using SOAP messages of request and response type, whose format is specified in the WSDL definition.
- Because both the client and server adhere to the WSDL contract when SOAP messages are created, guaranteeing that the messages are consistent.
- SOAP protocol is being continuously improved and standardized in order to achieve more effective interoperability.
Universal Description Discovery and Integration (UDDI)

- UDDI (Universal Description Discovery and Integration) makes publication easy to search and locate available Web services to be called, is a standard sponsored by OASIS (Organization for the Advancement of Structured Information Standard).
- Often described as the Yellow Pages of Web services, UDDI is a specification for creating an XML-based registry, presenting information about organizations and web services they offer.
- UDDI provides organizations a uniform way by which they can present their services and discover services offered by other organizations.
- Although implementations can vary, ussualy UDDI describes services using WSDL and communicate via SOAP messages.
- UDDI can be a private service within an organization or function as a public service on the Internet.
- Registering a Web service in UDDI registry is an optional step.
- To search a web service, a developer can query the UDDI registry to obtain the WSDL for the service that wants to use.
- Developers can also design their Web services so that customers receive automatic updates on any changes of a service in a UDDI registry.
Service-Oriented Architecture (SOA)

- SOA (Service Oriented Architecture - software architecture based on services) is a type of software architecture that involves distributing application functionality into smaller, distinct units - called service - that can be distributed in a network and can be used together to create applications for business5 .
- The large capacity of these services that can be reused in different applications is a feature of service-based software architectures.
- These services communicate with each other by sending information from one service to another.
- SOA is often seen as a solution to distributed programming and modular programming.
- SOA is a flexible, standardized architecture that contribute to better connect the various applications and facilitates the exchange of information between them.
- SOA unifies business processes by structuring large applications in a collection of small modules called services.
- These applications can be used by different groups of people both within and outside their company.
- Typically are implemented functionality that most people would know that service such as for example: completing an application online for an account, view a form or a bank account statement online or make an order of an air ticket online.
- Main factors that ensure the SOA projects success are evaluating technology options, design, development, delivery and administration.
- In addition, the need to clearly understand the service-oriented processing must be complemented by understanding their own development environments, the constraints and strategic objectives, to determine the optimal platform to achieve these objectives.
12. RPC Vs RMI
Remote Procedure Call
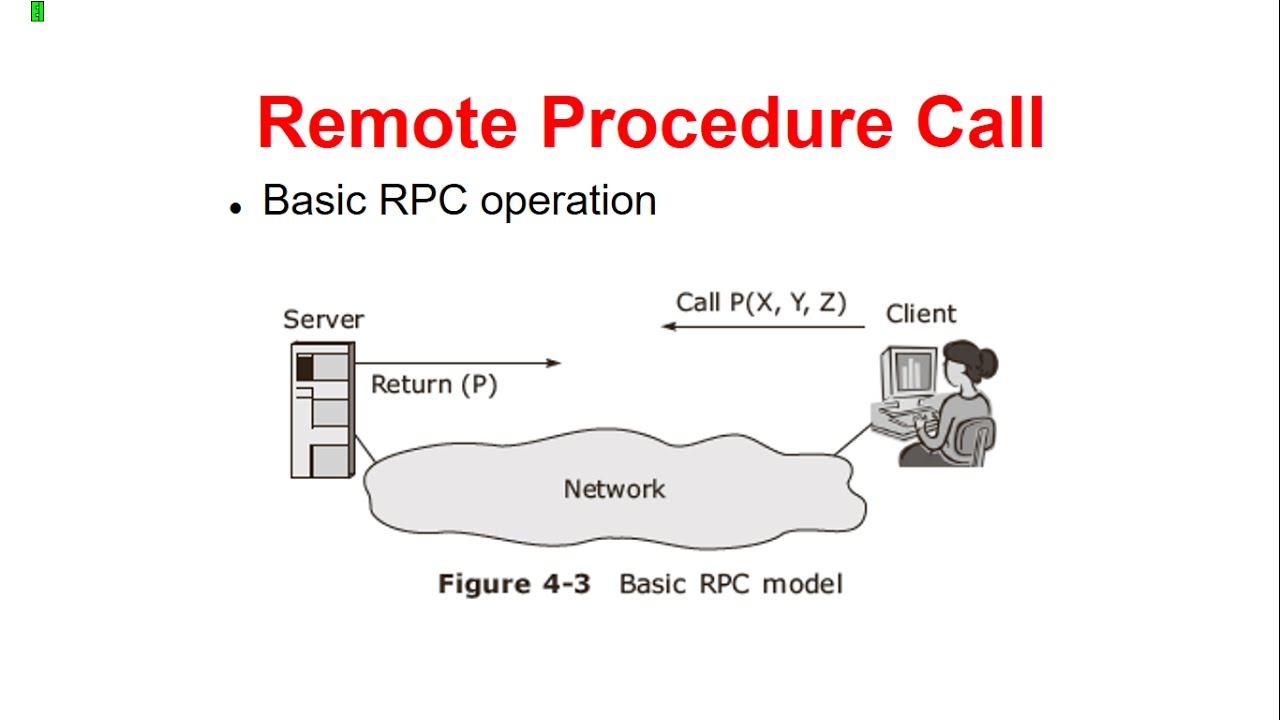
- Remote Procedure Call (RPC) is a protocol that one program can use to request a service from a program located in another computer on a network without having to understand the network's details.
- A procedure call is also sometimes known as a function call or a subroutine call.
- RPC uses the client-server model.
- The requesting program is a client and the service providing program is the server.
- Like a regular or local procedure call, an RPC is a synchronous operation requiring the requesting program to be suspended until the results of the remote procedure are returned.
- However, the use of lightweight processes or threads that share the same address space allows multiple RPCs to be performed concurrently.
Remote Method Invocation
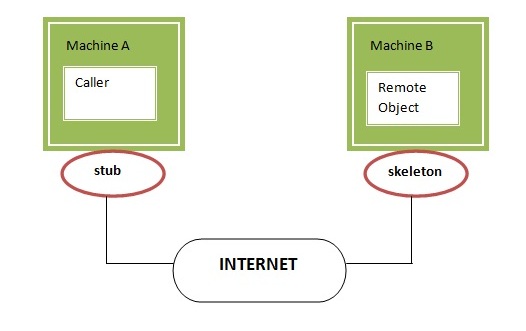
- The RMI (Remote Method Invocation) is an API that provides a mechanism to create distributed application in java.
- The RMI allows an object to invoke methods on an object running in another JVM.
- The RMI provides remote communication between the applications using two objects stub and skeleton.
- RMI uses stub and skeleton object for communication with the remote object.
- A remote object is an object whose method can be invoked from another JVM.
Now let's a take a look at differences betweeen RPC and RMI.
RPC |
RMI |
|---|---|
|
|
|
|
|
|
|
|
|
|
Key Differences
- RPC supports procedural programming paradigms thus is C based, while RMI supports object-oriented programming paradigms and is java based.
- The parameters passed to remote procedures in RPC are the ordinary data structures. On the contrary, RMI transits objects as a parameter to the remote method.
- RPC can be considered as the older version of RMI, and it is used in the programming languages that support procedural programming, and it can only use pass by value method. As against, RMI facility is devised based on modern programming approach, which could use pass by value or reference. Another advantage of RMI is that the parameters passed by reference can be changed.
- RPC protocol generates more overheads than RMI.
- The parameters passed in RPC must be “in-out” which means that the value passed to the procedure and the output value must have the same datatypes. In contrast, there is no compulsion of passing “in-out” parameters in RMI.
- In RPC, references could not be probable because the two processes have the distinct address space, but it is possible in case of RMI.

13. CORBA
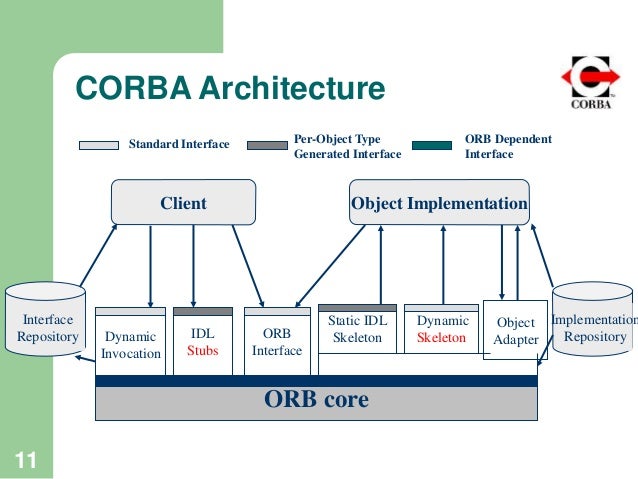
- CORBA, as defined by the Object Management Group (OMG) since 1992, is an open, vendor-independent architecture and infrastructure for distributed object technology.
- It is widely used today as the basis for many mission-critical software applications.
- CORBA vendors have progressively added richer quality-of-service features through the implementation of various CORBA services, like transactions and security.
- While CORBA may be the best solution for certain applications, developers often face the significant challenge of Web-enabling these systems.
- Few client-side, Internet-access products support IIOP.
- Even if IIOP is available (either preinstalled or downloaded), it is not firewall-friendly
- Because IIOP proxies are not widely installed on firewalls, these packets may need to be filtered out before reaching the intended server.
- Additionally system administrators are reluctant to open an IIOP route through the firewall, because it exposes another potential access point for malicious attacks and complicates filtering.
- Another issue faced by organizations is the mismatch between the skills of Web developers and authors, and the skills required to build CORBA systems.
- The typical Web developer may be content using HTML, JavaScript and Visual Basic.
- Such developers are often uncomfortable building CORBA clients, which require advanced Java or C++ skills.
- The problem is that much of the business logic they wish to expose, access, or reuse is implemented in CORBA with IDL interfaces!
- Because Web Services and CORBA standards are very similar, CORBA users can feel confident that their technical skills can be easily transferred to this new development model, which includes WSDL, SOAP and UDDI. More importantly, CORBA users have the very rare, yet critical, skills necessary to understand the complexity involved in building distributed systems.
- Making interface design and architectural decisions can impact performance, security, and systems management.
- These skills, which are essential when conducting Web Services projects, are typical among CORBA developers and architects.
14. XML

- Extensible Markup Language (XML) promises to simplify and lower the cost of data interchange and Web publishing.
- XML is predicted to play a dominant role as a data interchange format in business-to-business (B2B) Web applications, such as e-commerce and enterprise application integration (EAI).
- XML is the key to all the other Web Services standards, because it represents a truly interoperable data representation, allowing disparate applications to communication across the enterprise or the internet.
XML element naming conventions

- An XML document contains XML Elements.
- An XML element is everything from (including) the element's start tag to (including) the element's end tag.
<price>29.99</price>
- An element can contain:
- text
- attributes
- other elements
- or a mix of the above
- In XML, you can indicate an empty element like this:
<element></element>
- You can also use a so called self-closing tag:
<element/>
- XML elements must follow these naming rules:
- Element names are case-sensitive
- Element names must start with a letter or underscore
- Element names cannot start with the letters xml (or XML, or Xml, etc)
- Element names can contain letters, digits, hyphens, underscores, and periods
- Element names cannot contain spaces
Best Name Practices
- Create descriptive names, like this: <person>, <firstname>, <lastname>.
- Create short and simple names, like this: <book_title> not like this: <the_title_of_the_book>.
- Avoid "-". If you name something "first-name", some software may think you want to subtract "name" from "first".
- Avoid ".". If you name something "first.name", some software may think that "name" is a property of the object "first".
- Avoid ":". Colons are reserved for namespaces (more later).
- Non-English letters like éòá are perfectly legal in XML, but watch out for problems if your software doesn't support them.
- An element name can contain any alphanumeric characters. The only punctuation mark allowed in names are the hyphen (-), under-score (_) and period (.).
- Names are case sensitive. For example, Address, address, and ADDRESS are different names.
- Start and end tags of an element must be identical.
- An element, which is a container, can contain text or elements as seen in the above example.
15. XML Vs. JSON
Json
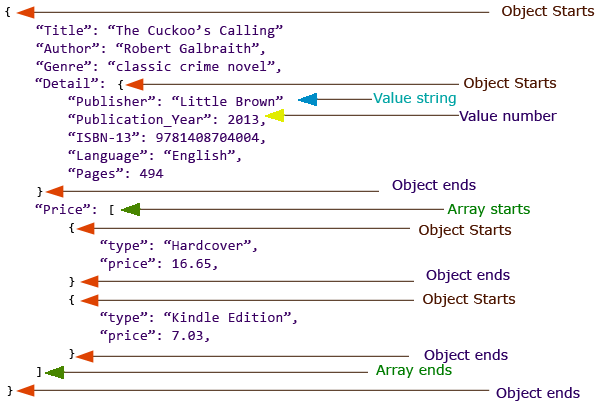
- JSON (JavaScript Object Notation) is a lightweight data-interchange format.
- It is easy for humans to read and write. It is easy for machines to parse and generate.
- It is based on a subset of the JavaScript Programming Language, Standard ECMA-262 3rd Edition - December 1999.
- JSON is a text format that is completely language independent but uses conventions that are familiar to programmers of the C-family of languages, including C, C++, C#, Java, JavaScript, Perl, Python, and many others. These properties make JSON an ideal data-interchange language.
- JSON is built on two structures:
- A collection of name/value pairs. In various languages, this is realized as an object, record, struct, dictionary, hash table, keyed list, or associative array.
- An ordered list of values. In most languages, this is realized as an array, vector, list, or sequence.
- These are universal data structures.
- Virtually all modern programming languages support them in one form or another.
- It makes sense that a data format that is interchangeable with programming languages also be based on these structures.
What are the differences between JSON and XML?
JSON |
XML |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
XML Pros And Cons
- XML's biggest advantage is that it provides developers with a tool that concisely and unambiguously defines the format of data records. If a company decides it is in its best interests to have devices built by other companies communicate with its own devices, it can support that capability by publishing its schemas. Since schemas are interpreted by software, human errors in interpretation are eliminated.
- Another advantage to XML is that it is a required building block for the Simple Object Access Protocol (Soap) and Universal Plug and Play (uPnP). Any device that will use uPnP to access or provide network services must support XML. XML is also used in many B2B applications and is therefore desirable for such embedded devices as POS terminals and inventory control scanners that need to communicate with B2B systems. There are also a large number of free tools available for XML, including many full-featured parsers.
- XML's biggest disadvantage is that its parsers tend to be very large, although the large memory footprint of XML parsers may be reduced to a reasonable size by eliminating unneeded features.
- The larger size of XML data records may be an issue for some applications. This can be dealt with by compressing the data before transmitting it or writing it to disk. There are many public domain compression algorithms.
JSON Pros and Cons
- Fully automated way of de-serializing/serializing JavaScript objects, minimum to no coding.
- Very good support by all browsers
- Concise format thanks to name/value pair -based approach
- Fast object de-serialization in JavaScript (based on anecdotal evidence )
- Supported by many AJAX toolkits and JavaScript libraries
- Simple API (available for JavaScript and many other languages)
- No support for formal grammar definition, hence interface contracts are hard to communicate and enforce
- No namespace support, hence poor extensibility
- Limited development tools support
16. Data Formatting and Structuring Techniques
In-place sorting and not in place sorting

- Sorting algorithms may require some extra space for comparison and temporary storage of few data elements.
- These algorithms do not require any extra space and sorting is said to happen in-place, or for example, within the array itself.
- This is called in place sorting. Bubble sort is an example of in place sorting.
- However, in some sorting algorithms, the program requires space which is more than or equal to the elements being sorted.
- Sorting which uses equal or more space is called not-in-place sorting. Merge-sort is an example of not-in-place sorting.
Stable and not stable sorting
- If a sorting algorithm, after sorting the contents, does not change the sequence of similar content in which they appear, it is called stable sorting.
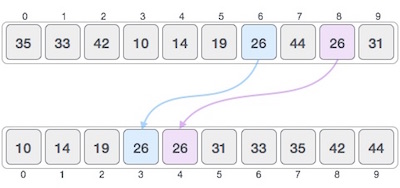
- If a sorting algorithm, after sorting the contents, changes the sequence of similar content in which they appear, it is called unstable sorting.
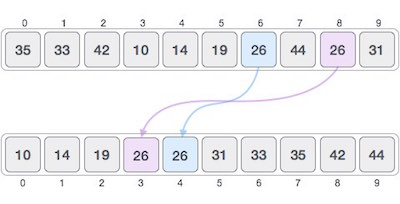
- Stability of an algorithm matters when we wish to maintain the sequence of original elements, like in a tuple for example.
Adaptive and non-adaptive sorting algorithm
- A sorting algorithm is said to be adaptive, if it takes advantage of already 'sorted' elements in the list that is to be sorted.
- That is, while sorting if the source list has some element already sorted, adaptive algorithms will take this into account and will try not to re-order them.
- A non-adaptive algorithm is one which does not take into account the elements which are already sorted.
- They try to force every single element to be re-ordered to confirm their sortedness.
No comments:
Post a Comment